|
|
|
안녕하세요, AI 서비스 & 솔루션 프로바이더 베스핀글로벌입니다.
AWS re:Invent 2025의 [COP336]을 확인해보시기 바랍니다.
|
☑️ Keynote
| 세션명 |
Elevating application reliability |
| 세션코드 |
COP336 |
| 발표일자 |
2025.12.07 |
| 강연자 |
Jay Joshi, Matheus Canela |
| 키워드 |
Resilience, Observability, Downtime, Generative AI, SLO, Anomaly Detection, CloudWatch Application Signals, CloudWatch Investigation |
|
핵심 내용
및 요약
|
ㆍ 시스템 다운타임은 기업에 막대한 재정적 손실(시간당 최대 5백만 달러)을 발생시키고, 고객 관계 및 브랜드 평판에 부정적인 영향을 미치므로 비즈니스 생존에 필수적이다.
ㆍ복원성 있는 아키텍처는 다중 AZ 중복성(ELB, RDS Multi-AZ), 인프라를 코드로 관리하는 IaC, 부하 급증에 대비한 자동 확장, 관리형 서비스 활용, 그리고 Fault Injection Service나 Resilience Hub를 통한 게임 데이 테스트가 핵심입니다.
ㆍ애플리케이션 안정성을 위해서는 비즈니스 영향, 사용자 경험, 서비스 상태 등 중요 신호를 측정하고, SLO(서비스 수준 목표)를 정의하며, CloudWatch Application Signals 및 AI 기반 CloudWatch 조사 기능을 활용하여 문제를 신속하게 감지, 진단 및 해결해야 합니다. |
|
오늘날의 디지털 환경에서 시스템 다운타임은 단순한 불편함을 넘어 막대한 비즈니스 손실로 이어질 수 있습니다. 이번 세션에서는 시스템의 복원력을 높이고, 효과적으로 문제를 관찰하며, 궁극적으로 생성형 AI(GenAI)를 활용하여 문제를 해결하는 방법에 대해 심도있게 설명합니다.
|
1. 다운타임으로 인한 손실과 복원력의 중요성
기업의 9%는 다운타임 시간당 30만 달러 이상, 41%는 시간당 100만 달러에서 500만 달러 사이의 손실을 보고 있습니다. 이는 단순한 금전적 손실을 넘어 기회 상실, 고객 관계 손상, 생산성 저하, 브랜드 평판 손상으로 이어집니다.
시스템 오류는 단순한 IT 문제가 아니라 기업의 생존과 직결되는 핵심 이슈입니다. 따라서 복원력 있는 시스템 구축은 필수적입니다.
|
2. 복원력의 기초 및 모범 사례
2-1. 단일 장애점 피하기
개인적인 경험 사례(홈 컨트롤러)를 통해 단일 장애점이 전체 시스템 장애로 이어질 수 있음을 강조합니다.
• 다중 AZ 아키텍처: AWS 환경에서는 독립적인 장애 도메인인 가용 영역(AZ)을 활용하여 중복성을 확보하고 복원력을 높이는 것이 중요합니다.
• Elastic Load Balancing: 한 AZ의 장애 발생 시 다른 AZ의 정상 노드로 로드를 이동합니다.
• RDS 다중 AZ: 데이터베이스 인스턴스 장애 시 다른 AZ로 자동 전환됩니다.
• IaC: 수동 클릭 대신 CDK(Cloud Development Kit)와 같이 코드로 인프라를 관리하여 인적 오류를 줄이고 안정적인 배포를 가능하게 합니다.
• 자동 크기 조정(Auto Scaling): 웹 서버나 애플리케이션에 로드가 급증할 경우, 자동으로 리소스를 추가하거나 제거하여 과부하에 유연하게 대처합니다. (EC2, Aurora 읽기 전용 복제본, Lambda, DynamoDB 등)
• Manaed Service 활용: Lambda, DynamoDB와 같은 관리형 서비스를 사용하면 인프라 관리에 대한 부담 없이 요청 처리에 집중할 수 있습니다.
2-2. 게임 데이(Game Day)
AWS Fault Injection Service(FIS)를 사용하여 의도적으로 환경에 오류를 주입하고, AWS Resilience Hub를 통해 애플리케이션의 복원력을 평가하며, 실제 장애 상황에 대비하는 훈련의 중요성을 강조합니다.

2-3. Reliability improvement cycle

• Resilient Architecture 구성
• Observe: 수집할 수 있는 지표가 무엇인지, 플랫폼을 통해 얻을 수 있는 정보가 무엇인지 고려
• Detect: Alert 발생 여부를 확인할 수 있는지, 알림을 받도록 구성되어 있는지 고려
• Investigate: 근본 원인을 찾을 수 있는지
• Resolve: 어떻게 하면 다시 되돌아 갈 수 있을지
|
3. 효과적인 관찰 가능성(Observability)
3-1. 복잡한 분산 시스템 관리
마이크로서비스 및 분산 시스템은 여러 서비스 간의 복잡한 통신으로 인해 문제가 발생했을 때 원인 파악이 어렵습니다. 또한, 적절한 관찰 가능성 없이는 시스템 문제를 추측에 의존하게 되므로, 애플리케이션 안정성 향상을 위해 다음 세 가지 핵심 신호를 측정해야 합니다.
• 비즈니스 지표: 수익 영향, 거래 수, 주문 수 등 비즈니스 결과와 직접 관련된 지표. (예: 결제 서비스 오류 시 손실되는 주문 수)
• 사용자 경험 지표: 핵심 웹 중요 지표(Core Web Vitals)와 같이 고객이 애플리케이션을 어떻게 경험하는지 나타내는 지표. (예: 최대 콘텐츠 페인트 시간 증가)
• 서비스 상태 지표: 요청 수, 오류 수, 대기 시간(P50, P95, P99 백분위수) 등 서비스의 성능과 건강 상태를 나타내는 지표. (평균보다는 백분위수 사용 권장)
3-2. SLO (서비스 수준 목표) & SLI (서비스 수준 지표)
• SLO: 최종 고객에게 약속하는 서비스 가용성 목표
(예: "우리 플랫폼은 99.5% 시간 동안 가동될 것입니다.")
• SLI: SLO를 달성하는 데 필요한 실제 측정 가능한 지표 (예: 대기 시간, 오류율, 가동 시간).
• 오류 예산(Error Budget): 고객 약속(SLA)과 내부 서비스 목표(SLO) 간의 차이로, 새로운 기능 배포 등의 활동에 사용할 수 있는 허용 가능한 실패율.
3-3. Amazon CloudWatch Application Signals


애플리케이션 코드를 변경할 필요 없이 OpenTelemetry 자동 계측을 사용하여 시스템의 상태와 성능을 모니터링 할 수 있으며, 서비스의 모든 지표와 추적을 자동으로 추출하고, 서비스 토폴로지 시각화, 사전 구축된 대시보드, SLO 추적 기능을 제공합니다.
CloudWatch Application Signals 를 통해 한 요청이 어디로 전달되는지, 어디서 오류가 발생되었는지, 실제 서비스가 어떻게 연결되었는지 등을 알 수 있습니다.
|
4. 신속한 오류 감지 방법 (Detect)
장애는 불가피합니다. 분산 시스템에서 장애는 언제든 발생할 수 있으므로, 고객이 불만을 제기하기 전에 최대한 빨리 이를 감지하는 것이 중요합니다.
4-1. 지연 지표(Lagging Indicators) vs. 선행 지표(Leading Indicators)

• 지연 지표: 이미 문제가 발생했음을 알려주는 지표. (예: 오류율 급증, 서비스 중단) 대부분의 팀은 여기서부터 시작합니다.
• 선행 지표: 문제가 발생할 것임을 알려주어 고객에게 영향을 미치기 전에 미리 조치할 시간을 주는 지표. (예: API 대기 시간 점진적 증가, 디스크 사용률 꾸준한 증가)
4-2. Anomaly detection with Amazon CloudWatch

• 로그 이상 감지(Logs Anomaly Detection): 머신러닝 알고리즘을 사용하여 애플리케이션 로그 내에서 발생하는 모든 예상치 못한 패턴과 이상을 지속적으로 감지합니다.
• 메트릭 이상 감지(Metric Anomaly Detection): 메트릭의 과거 값을 학습하여 기준 행동을 예측하고, 메트릭이 예상 범위를 벗어날 때 이상으로 표시하여 알람 피로를 줄입니다.

• 로그 패턴 및 비교(Log Patterns and Compare): 유사한 로그 이벤트를 패턴으로 그룹화하고, 과거 기간과 비교하여 패턴의 변화를 통해 시스템 변경 사항을 파악합니다.
• Contributor Insights: 로그에서 성능 저하를 유발하는 인스턴스, 네트워크 대역폭을 가장 많이 사용하는 사용자, 가장 많은 오류를 발생하는 API 엔드포인트 등 상위 기여자(Top N)를 식별하여 근본 원인 분석을 돕습니다.
|
5. GenAI를 활용한 원인 분석 (Investigate)
5-1. CloudWatch Investigation
기존의 방식은 수많은 알림이 발생하면 여러 데이터(메트릭, 로그, 추적)를 찾아보고 근본 원인을 파악하는 데 많은 시간과 노력이 소요됩니다. 하지만 CloudWatch Investigation 기능을 통해 모든 원격 측정 데이터를 자동으로 스캔하고 상관관계를 파악하는 데 도움을 받을 수 있습니다.

5-2. CloudWatch Investigation Workflow
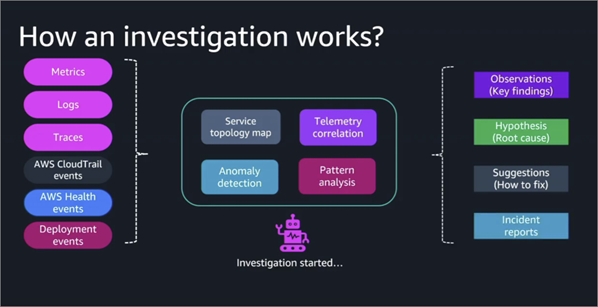
• 서비스 토폴로지 형성: 문제와 관련된 모든 서비스의 연결 관계를 파악합니다.
• 원격 측정 데이터 상호 연관: 메트릭, 로그, 추적, CloudTrail 이벤트 등 모든 관련 데이터를 수집합니다.
• 이상 징후 및 패턴 분석: 수집된 데이터에서 이상 징후와 오류 패턴을 감지합니다.
• 근본 원인 분석 및 가설 생성: 관찰 내용을 바탕으로 문제의 원인에 대한 가설과 해결 제안을 제공합니다.
• AI Agent 활용: AI Agent가 여러 메트릭을 수집 및 확보한 후 원인에 대한 가설을 세우고 진단하여 문제를 해결하는 방법에 대한 조치 사항까지 안내합니다.
|
6. GenAI를 활용한 문제 해결 (Kiro CLI 데모)

Kiro CLI: 터미널에서 실행되는 AI 에이전트 방식으로, LLM(거대 언어 모델)을 사용하여 시스템 문제를 진단하고 해결 명령을 실행합니다.
6-1. 데모 시나리오 (ECS 컨테이너 장애):
• 문제 발생: 음성 번역 애플리케이션에서 사용자가 세션을 생성하지 못하는 문제가 발생합니다.
• QCLI 진단: QCLI는 프롬프트(세션 생성 시뮬레이션 요청)를 받아 AWS CLI를 쿼리하고, Route 53, 로드 밸런서 등을 거쳐 백엔드 ECS 클러스터에 문제가 있음을 파악합니다.
• 근본 원인 식별: ECS 서비스의 원하는 개수(desired count)가 0으로 설정되어 컨테이너가 실행되고 있지 않음을 정확히 찾아냅니다.
• 문제 해결: QCLI에게 원하는 개수를 1로 변경하도록 명령하자, QCLI는 해당 명령을 실행하고 컨테이너가 다시 정상 작동하면서 세션 생성이 성공적으로 이루어집니다. 이 과정은 AI가 인프라 정보를 자동으로 파악하고 문제를 해결하는 능력을 보여줍니다.
|
7. 주요 요약 및 결론
• 복원력: 단일 장애점을 피하고, 다중 AZ, IaC, 자동 크기 조정을 통해 탄력적인 아키텍처를 구축하며, 게임 데이를 통해 대비해야 합니다.
• 관찰 가능성: 비즈니스, 사용자 경험, 서비스 상태 지표를 측정하고 SLO/SLI를 정의하여 시스템을 깊이 이해해야 합니다.
• AI Ops: CloudWatch Application Signals, 이상 감지, Contributor Insights, CloudWatch 조사, QCLI와 같은 GenAI 도구를 활용하여 문제를 신속하게 감지, 조사, 해결함으로써 운영 효율성을 극대화합니다.
• 비즈니스 연계: IT 부서뿐만 아니라 비즈니스 팀과 협력하여 SLA/SLO를 정의하고, 고객의 입장에서 시스템의 중요도를 파악하는 것이 중요합니다.
|
|
|