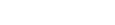|
|
안녕하세요, AI 서비스 & 솔루션 프로바이더 베스핀글로벌입니다.
AWS re:Invent 2025의 [AI-Driven Operations: Scaling Observability and Cost Optimization]을 확인해보시기 바랍니다.
|
☑️ Keynote
| 세션명 |
AI-Driven Operations: Scaling Observability and Cost Optimization |
| 세션코드 |
GBL201 |
| 발표일자 |
2025.12.03 |
| 강연자 |
Hyeyoung Park, Young Seop Lee, Shinhyuk Seo |
| 키워드 |
1. AWS GenAI 인프라 및 기술 업데이트
2. Bedrock (AgentCore)
3. Strands Agents
4. ClickHouse |
| 핵심 내용 및 요약 |
ㆍAmazon Bedrock과 같은 최신 생성형 AI 서비스는 물론, AI 모델의 구축, 학습, 배포 및 MLOps 전반을 지원하는 AWS의 포괄적인 서비스 포트폴리오를 활용하여 에이전트 아키텍처(Agent Architecture) 및 멀티 에이전트 시스템(Multi-Agent System)의 도입을 통해 복잡하게 얽힌 클라우드 환경의 운영 데이터를 효율적으로 수집, 분석하는 실질적인 방법론을 제시하고. 이를 통해 운영 효율성을 획기적으로 향상시키고, 비용을 절감할 수 있는 구체적인 아키텍처와 실행 가능한 자동화 전략에 대한 정보를 제공합니다. 실제 운영 환경에서 비용을 절감하고 시스템 안정성을 높이는 실용적인 인사이트를 제공합니다. |
|
AI-Driven Operations: Scaling Observability and Cost Optimization
|
1. AWS GenAI 인프라 및 기술 업데이트
 1-1. 생성형 AI 인프라스트럭처 레이어 업데이트 1-1. 생성형 AI 인프라스트럭처 레이어 업데이트
- Trainium 3 칩 공개 - 전 세대(Trainium 2)보다 성능이 향상되었습니다.
- Ultracluster 서버 - Trainium 3 칩 144개 탑재되었습니다.
- NVIDIA Grace Blackwell GPU(GB200, GB300) 기반 인스턴스가 P3 EC2 인스턴스에 적용되었습니다.
1-2. Amazon SageMaker 업데이트
- 모델 학습–배포–운영 전체 생명주기 자동화 환경으로 활용 가능합니다.
- Serverless Customization 기능 추가로 서버리스 방식으로 모델 커스터마이징 가능합니다.
- HyperPod 무중단 체크포인트리스 학습으로 중간 실패(Spot 중단 등) 발생 시 재학습 필요 없이 이어서 학습 가능합니다.
1-3. Amazon Bedrock 모델 업데이트

- 총 20개 이상 모델 제공 및 10만 명 이상 고객이 사용하고 있습니다.
- Mistral 모델 4종 업데이트되었습니다(Mistral Large3 포함)
- Nova 2세대 모델군 4종 공개되었습니다(2 Light, 2 Pro, Nova Sonics, Nova Omni)
- Nova Forge : 사후 튜닝 방식과 달리, 모델의 특정 체크포인트(앞·중간·뒤)에 고객 데이터를 삽입하여 성장 과정 자체를 커스터마이징 가능합니다.
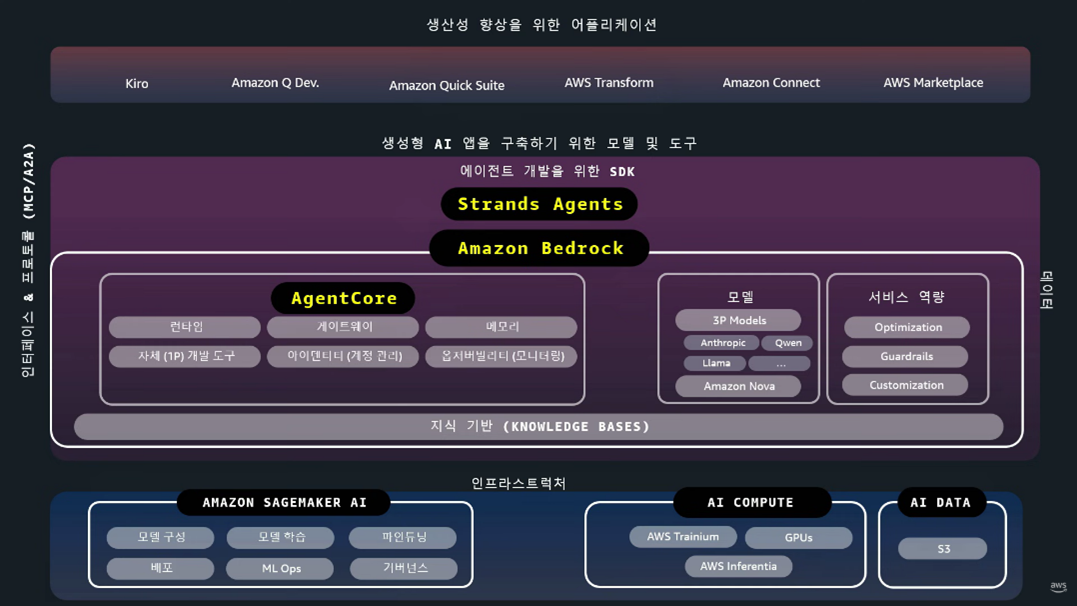
1-4. Strands Agents
- 몇 줄의 코드만으로 에이전트를 구축할 수 있는 오픈 소스 파이썬 기반 SDK입니다.
- TypeScript 지원 추가되었습니다.
- Edge Device 지원: 오프라인 환경에서도 에이전트 실행이 가능합니다.
- 복잡한 Agentic Loop(연속 대화, 조건 분기, 도구 연계 등) 코드가 매우 단순화되었습니다.
1-5. Agent Core

- 어떤 프레임워크와 모델을 사용하더라도 안전하게 확장 가능한 고효율 에이전트를 배포하고 운영하기 위한 도구입니다.
- 주요 제공 기능
- Runtime: 에이전트 실행 환경, 최대 8시간 연장된 런타임 제공, 멀티 모달 페이로드 지원, 보안 제어
- Gateway : 리소스를MCP(Multimodal/Model Context Protocol) 호환 툴로 자동 변환, 외부 자동 도구 연결
- Memory : 세션 단기 메모리
- Identity : 필요한 만큼의 접근 권한, 타사 도구/서비스의 안전한 접근
- Observability : 에이전트의 성능을 추적, 디버그 및 모니터링
- Browser : 웹 액세스를 통해 에이전트가 웹사이트와 상호작용
- Code Interpreter : 샌드박스 Python/코드 실행
- 추가 업데이트 기능
- Policy System(정책 제어 프레임워크) : Gateway에 정책 삽입되었습니다.
- Eval(평가·품질관리) : AI가 생성하는 결과물의 품질을 정량 평가, 기준 관리가 가능합니다.
- Episodic Functionality (장기 기억) : 과거의 경험까지 장기 경험을 축적하여 에이전트가 더 똑똑해졌습니다.
|
2. 삼성전자 MX사업부 사례: AI 기반 클라우드 비용 효율화 및 운영 자동화
2-1. 삼성전자 AWS 사용 현황 및 문제 의식
- 2009년 Galaxy 시리즈 시작과 함께 AWS를 도입하였습니다.
- Samsung Health, Samsung Pay, SmartThings, Bixby, Smart Cloud 동기화, RCS, Galaxy AI 등을 포함하여 현재 150개 이상의 서비스가 AWS에서 운영되고 있습니다.
- 매년 10% 이상 비용이 증가되었으며, 2024년 Galaxy AI 출시 후 사용량·비용이 급증하였습니다.
2-2. Galaxy AI 성공과 함께 발생한 예상치 못한 문제
- 개발 조직: 개발 일정 우선 → 시스템 장애/비용 무관심, 장애 공동 대응/비용에 대한 회피가 발생하였습니다.
- 운영 조직: 안정성 우선 → 안정성과 비용 효율화를 동시 만적 Needs에 대한 Balancing이 필요했습니다.
- 재무 조직: 클라우드 ROI 측정 불가, 클라우드 예산 통제가 어려웠습니다.
- 결과적으로 FinOps 비용 최적화, AI-Ops 운영 자동화(이상 징후 감지) 혁신 목표를 수립하게 되었습니다.
2-3. 삼성전자 FinOps with Bixby사례
- Unit Cost 지표 정의
- Unit Cost : 총 비용 / Transaction 수 (트랜잭션 1건당 비용)
- 비용은 증가하지만 트랜잭션이 더 빠르게 증가하면 Unit Cost 하락 → 서비스 활성화 + 효율적 운영이 가능해집니다.
- 비용과 트랜잭션이 동일하게 증가하면 Unit Cost 정체 현상이 발생합니다.
- 트랜잭션 증가 없이 비용만 증가하면 Unit Cost 상승 → 비효율 발생 → Unit Cost를 기반으로 클라우드 비용 효율성 분석 판단을 고려해야 합니다.
- Unit Cost 기반 클라우드 비용 효율성 분석을 위한 Bixby PoC
- Gravition Type 적용
- Idle / Unused 자원 삭제
- RI/SP 비율 확대
- DynamoDB RC 확대
- Transaction에 맞는 Scale-in/out (Seasonality 같은 파악을 통한 Scale In/Out으로 추가 절감)
- Client App의 API 호출 축소 Architecture 전환 → 연간 10.4% 비용이 절감되었습니다.
- Multi Agent Architecture
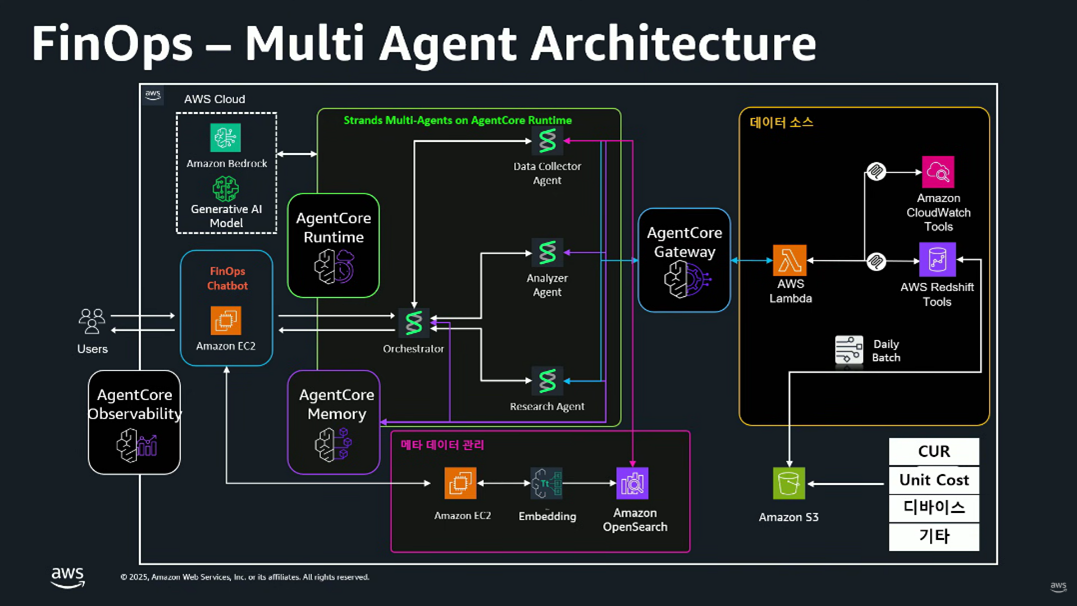
- AgentCore Runtime (Strands Multi-Agents)
- AWS Agent Core 런타임 기반 4개 Agent로 구성됩니다.
- Data Collector Agent : AWS CUR(RI/SP 데이터 포함), 서비스 메타데이터를 자동 수집합니다.
- Analyzer Agent : 사용자 자연어 질의를 이해합니다.
- Research Agent : OpenSearch, DynamoDB, Redshift, Cost & Usage 데이터를 조회합니다.
- Orchestrator Agent : 여러 에이전트의 응답 조합 → 최종 결과가 생성됩니다.
- 메타 데이터 관리
- OpenSearch : Vector DB에 반복 조회되는 메타데이터 캐싱을 지원합니다.
- 데이터 소스
- Amazon Redshift : AgentCore Gateway를 통해 MCP 프로토콜을 통해 CUR 데이터·서비스 메타데이터를 Daily Batch를 통해 적재된 데이터를 액세스합니다.
- 데모: 자연어 기반 비용 분석
- 프롬프트를 통해 Multi Agent Architecture가 적용된 FinOps를 통해 기존 1달 넘게 소요되었던 분석을 수분 단위로 수행 가능하게 되어 운영·재무 의사결정 속도가 크게 향상되었습니다.
2-4. 삼성전자 AIOps with 삼성 클라우드 사례
- 개발 배경
- 특정 앱 배포 후 점진적 이상이 증가했습니다.(일주일~한 달 후 장애 발생)
- Threshold 기반 기존 모니터링으로 감지가 어려웠습니다.
- 해결 방안
- 자체 ML 모델로 신규 배포 이후의 패턴 변화를 학습시켰습니다.
- 예상 패턴과 다른 증감을 조기에 감지 → 사전 티켓을 생성하였습니다.
- 앱 개발자가 즉시 수정하여 장애 예방에 성공하였습니다.
- Multi Agent Architecture 확대 계획
- Anomaly Detection : 이상징후 감지(클라우드 설계/구성 Drift 자동 감지)를 통한 장애 예방이 가능합니다.
- Cloud 형상 관리 : 보안 취약점 점검을 자동화합니다.
- Cloud 장애 원인 분석 (RCA)
- Cloud 장애 복구 추천 (중요도 기반 장애 등급 자동 분류 및 장애 복구 시나리오 자동 추천)
→ FinOps멀티에이전트 아키텍처를 AIOps까지 확장하고, 이번 re:Invent에 공개된 Security Agent, DevOps Agent도 도입을 통해 운영 안정성/보안 수준 대폭 상승될 것으로 전망합니다.
2-5. 삼성전자 AI 도입 과정을 통한 Lessons & Learned
- 명확한 비전과 소통을 통한 리더십 혁신 필요
- 현실적으로 목표·기대치를 명확히 설정하고 점진적 성과를 공식 인정해야 합니다.
- 조직 간 충돌(개발/운영/재무)의 해소가 가능합니다.
- “필요할 때만 AI 사용” 하지 않고Process 내 AI 도입(상시 적용)
- 필요 시 AI 사용하는 경우, 기존 방식(수작업)을 계속 사용하게 해야 합니다.
- 업무 프로세스를 분석하여 AI 기반으로 재설계를 통해 지속적이고 실질적인 업무 생산성 향상이 가능합니다.
- AI의 80%는 “데이터 준비, 파이프라인 생성”
- 잘못된 데이터 → 잘못된 판단으로 이어집니다.
- 데이터 품질을 위한 데이터 거버넌스, 품질 관리 체계 구축이 필요합니다.
- 최신 기술 = 최적의 기술이 아니다
- 작은 데이터는 간단한 분석으로 충분합니다.
- 실시간 대규모 데이터는 에이전트 AI가 필요합니다.
- 상황·데이터 성격·보안요구에 맞는 적재적소 AI 도입이 핵심입니다.
2-5. Intelligent Cloud Ops 계획
- AIOps : AI 모니터링/예측적 이상징후 감지, AI 기반 Cloud 변경 리뷰 / 취약점 분석, AI 기반 장애복구/DR 추천
- SecOps with AI : 클라우드 AI 보안 솔루션 도입, AI 악성 행위 실시간 탐지, 자동화된 컴플라이언스
- FinOps with AI : AI 기반 비용 효율화 추천, Multi-Cloud 비용 통합 관리, AI 기반 비용 자동 배부
|
3. Kakao 사례 : AI-native Observability as Scale: Logging for 50 Million Users on EKS
3-1. 서비스 규모
- MAU 약 4,900만 (전 국민 사용 수준)
- 일부 시스템만 포함된 로그임에도 일 20TB 이상의 로그가 발생합니다.
- 3개월 저장 시 약 1.4PB(페타바이트) 용량이며, 15년간 지속된 서비스로 수백 개의 MSA 기반 서비스구조로 높은 복잡도를 가지고 있습니다.
3-2. 기존 로깅 시스템의 Pain Points
- Large-scale logs
- Elasticsearch 확장성 한계
- 수평 확장 시, 기하급수적으로 비용이 증가합니다.
- 스케일링 과정에서 잦은 re-indexing, re-balancing 작업으로 관리 복잡성이 증가합니다.
- 노드 수 제약으로 인한 스케일 아웃 시 클러스터 분리가 필요합니다.
→ 대규모 로그 처리에서 확장성과 비용 효율성에 한계가 있습니다.
- Loki 성능 한계
- Cardinality 높은 데이터 쿼리 시, 속도가 급격히 저하됩니다.
- 대규모 aggregation 작업 수행이 어렵습니다.
→ 복잡한 로그 분석 시, 성능 효율성 저하. 장애 대응/CS 대응 시 실시간 로그 분석이 어렵습니다.
- Observability 파편화
- 로그, 메트릭, 트레이스가 여러 곳에 분산되어 있어서 전체 시스템 상태를 한 눈에 파악하기 어렵습니다.
- 개발자는 장애 대응 시 'Loki/ES(로그)', 'Grafana/TSDB(메트릭)' 여러 화면을 오가며 머릿속으로 연관 분석 필요 → 장애 대응 속도가 저하되고 업무 피로가 증가합니다.
3-3. Observability 전략
- EKS 기반 중앙화
- ES+Kibana, Time-series DB, Loki 등에 분산 → 단일 인터페이스에서 모든 관찰성 데이터 확인 및 통합이 가능합니다.
- ClikHouse 통합 저장소
- 로그. 메트릭, 트레이스가 각각 다른 저장소에 분산 → 단일 인터페이스에서 모든 관찰성 데이터 확인 및 통합이 가능합니다.
- 스토리지 비용 급증
- ES 수평 확장 시 비용 급증 → Open Telemetry로 텔레메트리 수집을 표준화합니다.
- 수동적 로그 분석
- 수동 로그 분석 및 사람 경험 의존 패턴 분석 → 자연어 쿼리와 AI 에이전트 자동 RCA, 실시간 인사이트를 제공합니다.
3-4. 아키텍처 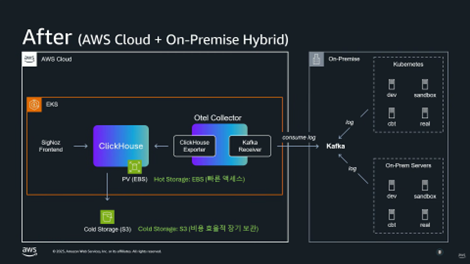
- Kafka
- AWS Cloud와 On-Premise를 연결합니다.
- 3일치 로그 버퍼링 및 로그 유실 방지 레이어 역할을 합니다.
- AWS OpenTelemerty Collector Cluster
- AWS EKS의 ClickHouse Cluster
- 수집된 로그를 저장합니다.
- Hot Storage는 빠른 액세스를 위해 EBS를 이용합니다.
- Cold Storage는 비용 효율적인 장기 보관을 위해 S3를 이용합니다.
- 통합 파이프라인
- Logs, Metrics, Traces 모두 통합 저장합니다.
- OpenTelemetry 기반 통일된 에이전트 관리가 가능합니다.
3-5. 카카오가 채택한 ClickHouse 기반 고가용성 전략
- 전략 내용
- ClickHouse Replica. 대신 ‘ClickHouse Backup/Restore 기능’ 과 ‘Kafka에 3일치 로그를 적재’ 하는 방식으로 채택하였습니다.
- 전략 채택 사유
- 대규모 로그 환경에서 Replica 구성 시 스토리지 비용이 2배 발생하고, 로그 규모가 크기 때문에 비용 임팩트가 치명적이기 때문입니다.
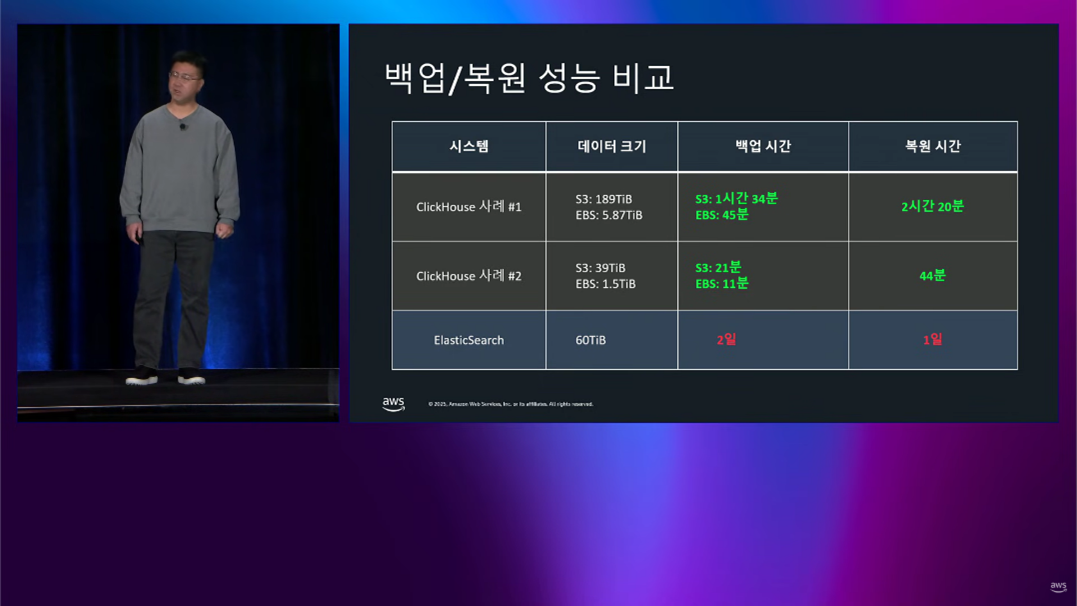
- Backup/Restore 소요시간 검증
- 기존의 Elasticsearch는 데이터 용량은 60TB, Backup/Restore에 각각 1일 이상 소요되며 장애 발생 시 복원하기 어려웠습니다.
- ClickHouse 사례 #1
- . 데이터 용량 : S3 – 189TB, EBS – 5.87TB로 증가, Backup의 경우에는 S3 - 1시간 34분, EBS : 45분이 소요되었습니다. Restore는 2시간 20분이 소요되었습니다.
- ClickHouse 사례#2
- 데이터 용량의 경우, S3 – 39TB, EBS – 1.5TB이었으며 Backup은 S3 - 21분, EBS 11분 Restore 44분이 소요되었습니다
- S3 내부에서 CopyObject API기능을 활용하여 네트워크 전송없이 S3 내부 데이터 복제 수행을 통해 초고속 Backup/Restore를 통해 매일 백업 + 장애 시 복구 전략으로 실현 가능합니다.
3-6. 인프라 및 비용 최적화
- 스토리지 테스트
- 하루 20TB 데이터 기준 디스크 요구사항을 산출했고 고성능 Provisioned IOPS 대신 GP3 스토리지로 충분한 성능을 확보할 수 있었습니다.
- Compute 최적화
- ClickHouse가 컬럼 기반 DB로 병렬처리하여 동일 가격 조건에서 ARM(Gravition)이 더 많은 vcpu를 제공했습니다.
- Graviton 계열이 Intel 대비 약 25% 성능 우수하면서 비용은 더 저렴합니다.
3-7. AI native observability 사례
- ClickHouse MCP & LLM
- LibreChat 기반, Clickhouse MCP, LLM 으로 구성하였습니다.
- 시스템 프롬프트 기반 도메인 지식을 제공합니다.
- ‘서비스 상태 분석해줘’ 와 같은 사용자의 요청에 LLM이 시스템 프롬프트에 포함된 문맥을 활용하여 특정 로그 패턴, 에러 추이, 응답 지연 등 자동 분석하여 그 내용을 상세 리포트로 제공합니다.
- ‘서비스 사용량 분석해줘’ 와 같은 사용자의 요청에 LLM이 자동으로 ‘요일별 트래픽 패턴, 시간대별 변화, 비정상 이용 변동’ 등을 분석하여 보고 → 기존에는 버려졌던 방대한 로그에서 Business Analytics 활용 가능성이 확인되어 조직 차원에서 하나의 통합 Log/BI 파이프 라인을 구상하고 있습니다.
3-8. 도입 효과
- 운영 효율 개선
- ES 7개 클러스터 → Clickhouse 1개 클러스터로 변경, 운영 난이도 및 인력 비용 대폭 감소하였습니다.
- 리소스 절감
- vCPU는 ES 사용 시 800개에서 Clickhouse로 대체를 통해 128개로 절감되었습니다.
- 메모리는 ES 사용 시 3840GB에서 Clickhouse로 대체를 통해 512GB로 절감하며, 1/7 수준으로 리소스 사용량을 절감할 수 있었습니다.
- 성능 유지 혹은 향상
- High Cardinality 필드 기준 쿼리 수행 시 ES와 Clickhouse모두 28초 소요됨
→ 동일 성능
- Loki 대비 극적 분석 성능 향상
- Loki 사용 시 10분 소요되던 시간이 Clickhouse 사용 시 18초로 33배 성능 향상되었습니다.
→ 장애 대응/CS 대응 시 즉각적인 로그 분석이 가능해졌습니다.
3-9. 결론
- 현재 달성한 목표
- OpenTelemetry 기반 통합 수집 파이프라인 구축
- Logs / Metrics / Traces 통합 저장소 확보 (ClickHouse)
- 로그 중심 관찰성(Log-centric Observability) 완성
- AI 기반 로그 분석 기능 프로덕션 적용
- 향후 로드맵
- 통합 Observability Dashboard 구축
- 하나의 Query로 Logs/Metrics/Traces 동시 분석
- AI Agent 기반 장애 분석·예측 고도화
- 장애 원인 자동 추론
- 장애 구간 자동 식별
- 사전 이상 감지 및 경보
- 전사 로그 + BI 통합 플랫폼 확장
|
|
|