|
|
|
안녕하세요, AI 서비스 & 솔루션 프로바이더 베스핀글로벌입니다.
AWS re:Invent 2025의 [AIM272]을 확인해보시기 바랍니다.
|
☑️ Keynote
| 세션명 |
Master AI model development with Amazon SageMaker AI |
| 세션코드 |
AIM272 |
| 발표일자 |
2025.12.07 |
| 강연자 |
Ankur Mehrotra, Mark Andrews |
| 키워드 |
Amazon MSK (Managed Streaming for Apache Kafka), Apache Flink , Data Streaming, Scalability, Real-time Analytics, Serverless Streaming |
핵심 내용
및 요약 |
ㆍAmazon MSK(Managed Streaming for Apache Kafka)와 Amazon Managed Service for Apache Flink를 활용하여 대용량 스트리밍 데이터를 안정적이고 비용 효율적으로 운영하고 확장하는 엔지니어링 전략 및 모범 사례를 공유 |
|
1. 주요 문제
1-1. 핵심 문제
• 고객은 생성형 AI 모델에 접근하기 쉬워졌다 느끼지만 경쟁사도 동일한 모델을 사용할 수 있어 차별화를 만들기 어려운 것이 고민입니다.
• 차별화는 혁신과 고객 가치 창출의 핵심 요소
: 단순히 더 나은 AI를 구축하는 것이 아닌 자사와 비즈니스에 대해 깊이 이해하는 모델이 필요합니다.
1-2. 생성형 AI의 한계
• 기존 모델은 일반적인 지식은 많지만 개별 비즈니스의 데이터, 도메인 전문성, 트랜잭션 패턴, 제약조건 등에 대한 이해가 부족합니다.
|
2. 모델 학습 단계
• 사전학습 단계 : 방대한 텍스트와 다양한 데이터를 통해 다음 토큰 예측, 문법, 구문 등 학습합니다.
• 지침 학습 단계 : 입력-출력 쌍을 통해 지시를 따르는 방법, 구조적 설명, 도움 제공 능력 학습합니다.
• 선호 최적화 단계 : 단순 답변이 아닌 좋은 답변을 제공하도록 학습. 간결함, 명확성, 사회적 규범 준수 학습합니다.
• 추론 및 문제 해결 단계 : 암기에서 추론으로 전환. 강화학습 등 기법 사용합니다.
• 실무 적용 단계 : 학습한 지식을 실제 업무에 적용. 배포 후 LA(Learning Augmentation)이나 파라미터 튜닝을 통해 지속적인 학습 가능합니다.

|
3. 사전학습 상세 내용
3-1. 목표
• 다양한 데이터 소스로부터 방대한 토큰 학습합니다.
• 패턴 학습, 다음 토큰 예측, 문법·구문·사실 이해, 내부 표현 구축합니다.
• 모델 크기, 학습 단계 수, 컴퓨팅 파워, 데이터 양이 많을수록 일반화 능력과 성능 향상합니다.
• 특정 작업 수행이나 전문 지식 학습이 목표는 아닙니다.
• 단순해보이지만 복잡한 과정입니다.

3-2. 주요 도전 과제
• 효율적 확장 : 모델과 데이터가 커서 한 AI 가속기(GPU등)에 다 들어가지 않으며, 대규모 GPU 클러스터나 AWS 학습 인스턴스 등에서 효율적으로 학습을 분산해야합니다.
• 복원력 : 분산 학습에서는 모든 GPU가 하나의 모델 학습에 협력해야하며, 한 개의 GPU라도 실패하면 전체 학습 중단이 가능함. 인프라 안정성이 매우 중요합니다.
• 활용도 : GPU/AI 가속기 클러스터는 매우 비싸므로, 자원이 놀지 않도록 고효율 유지가 중요합니다.
• 생산성 : 엔지니어, 데이터 사이언티스트가 인프라 문제 대신 모델 개발에 집중할 수 있도록 도구 제공합니다.
• Observability : 학습 중 운영 상태 및 메트릭을 실시간으로 관찰할 수 있어야 합니다.
• Composability : 급속히 등장하는 최신 오픈소스 툴을 유연하게 통합할 수 있는 인프라 필요합니다.

|
4. SageMaker에서 모델을 학습하는 방식
• Training Job : 일시적 인프라로 학습 시작 시 리소스 생성, 종료 시 자동 반환합니다.
• Hyperpod : 지속적 GPU 클러스터로 장애 자동 복구 및 인프라 제어 가능합니다.

|
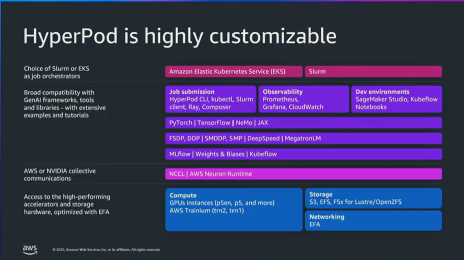
5. Hyperpod
5-1. Hyperpod란
• EKS/SLURM 등 익숙한 방식으로 작업을 관리합니다.
• 자동 장애 복구, 실시간 스케줄링, 모니터링 도구 통합합니다.
• 최신 GPU/Trainium, 다양한 스토리지, 주요 AI 프레임 워크 지원합니다.
• 엔지니어가 인프라 걱정 없이 모델 개발에 집중할 수 있도록 설계합니다.

5-2. Hyperpod가 필요한 이유
• 기존 문제 : 분산 사전 학습은 GPU 한 대만 고장나도 전체 학습 중단되므로 클러스터가 커질수록 장애 발생 확률이 증가하며 비효율적인 학습이 이루어지고 비용이 증가합니다.
• Hyperpod는 자동 대응 및 빠른 복구로 학습 중단 시간 최소화, 비용 절감, 개발 속도 향상 등의 이점이 있습니다.
5-3. HyperPod의 Self-Healing 기능
• 학습 중 노드 장애 발생 시 자동 감지 & 진단합니다.
• 필요하면 문제 노드를 자동 교체합니다.
• 마지막 체크포인트에서 자동 복구합니다.
• 별도 개입 없이 학습 자동 재시작합니다.
• 장애가 발생해도 중단 시간 최소화, 인력 개입 없이 지속 학습 가능합니다.
5-4. 아직 남아있는 문제
• All-or-Nothing : 하나의 노드가 장애가 나는 경우 전체 클러스터 중단합니다.
• 복구 단계가 순차적으로 진행 : 노드 교체 -> 체크포인트 복구 -> 재시작. 대기 시간 누적되어 복구 느립니다.
• 체크포인트 로딩 비용이 큼 : 최대 1시간 이상 지연됩니다.

5-5. 새로운 HyperPod에 도입된 기술 – Checkpointless Training
• 장애 발생 시 기존처럼 전체 중단하지않고 정상 노드들이 계속 학습을 수행합니다.
• 장애 난 노드는 근처 노드로부터 모델 상태를 P2P로 전송받아 복구합니다.
• S3의 checkpoint에 의존하지 않으며 인프라 재시작이 없어 프로세스 유지합니다.
• 장애 복구 시간은 수 초 이내이며 대규모에서도 2분 이내 이뤄집니다.
• 클러스터 효율은 95% 이상 지속적으로 달성합니다.

5-6. 핵심 기술
1) Optimized Collective Communication Initialization
- 중앙 Root 서버 없이 Peer-to-Peer 방식으로 노드 간 통신 채널을 자동 구성합니다.
- 초기화 속도 수분 → 수초
2) Memory-Mapped Data Loading
- 학습 데이터가 공유 메모리에 캐시되어 장애 이후에도 즉시 사용 가능합니다.
- 데이터 파이프라인 초기화 동안에도 훈련은 바로 재개합니다.
3) In-Process Recovery
- 장애 상황에서도 훈련 프로세스를 종료하지 않습니다.
- 단순히 일시정지 → 재개
4) Checkpointless Recovery
- 실패한 노드를 건강한 노드로 자동 교체합니다.
- 모델/옵티마이저 상태를 인접 노드 간 P2P로 복구합니다.
- S3 등 외부 Checkpoint에 의존하지 않습니다.


|
6. HyperPod Task Governance
6-1. 문제
• 대규모 사전 학습 환경에서는 인프라가 유휴 상태가 되는 문제가 자주 발생합니다.
• 비용 증가 및 개발자 생산성 저하됩니다.
6-2. HyperPod Task Governance의 해결
• 작업 우선순위 기반 자동 스케줄링 : 중요도가 높은 작업이 먼저 실행되어 리소스 낭비 방지합니다.
• 실시간 사용량 모니터링 : 클러스터 전체, 개별 작업, 팀 단위까지 관찰 가능합니다.
• 유휴 자원 자동 재활용 : 남는 GPU는 즉시 다른 작업에 할당합니다.
• 팀, 프로젝트 별 컴퓨팅 할당량 설정 : 팀 간 공정한 자원 사용 보장합니다.
• 대여/차용 규칙 : 다른 팀의 여유 자원을 자동으로 빌려쓰거나 빌려줄 수 있습니다.
• 고우선 순위 작업이 저우선 순위 작업 중단 가능 : 가장 중요한 작업이 지연되지 않도록 자동 조정합니다.

|
7. Hyperpod Elastic Training
7-1. 문제
• 분산 학습은 보통 노드 구성이 고정되어있어 학습 중간에 자원을 늘리거나 줄일 수 없다는 문제가 있습니다.
• 고우선순위 작업이 필요한 경우에도 자원을 뺄 수 없고 학습 중단 후 재구성하고 재시작해야합니다.
7-2. Elastic Training의 해결
• 노드 구성 탄력 조절 : 학습 중에도 노드를 자유롭게 추가/삭제 가능합니다.
• 중단 없는 확장/축소 : 학습을 멈추지 않고 속도 향상 또는 자원 회수 가능합니다.
• 자원 가용성 반영 : 여유 GPU가 생기면 자동으로 학습에 투입, 부족하면 자동 축소합니다.
• 고우선순위 작업 지원 : 다른 중요한 작업이 필요할 때 자원을 즉시 재배정합니다.
• 모델 품질 유지 : 데이터 병렬 replica 수만 변동하여 수렴에 영향 없이 진행합니다.

|
8. Hyperpod Observability
8-1. Observability 문제
• 학습 성능 저하 원인 파악에 수일 소요되는 경우 발생합니다.
• GPU 온도·네트워크 지연 등 하드웨어 레벨의 상태를 실시간으로 파악하기 어렵습니다.
• 학습 코드, 프레임워크, 네트워크, 하드웨어 등 다층 구조로 인해 원인 분석 난이도 증가합니다.
• 이상 징후 발생 시 즉각적인 대응이 어려워 효율 저하 발생합니다.
• 클러스터 규모가 커질수록 모니터링 구성 및 운영 부담 증가합니다.
8-2. HyperPod Observability의 해결
• 원클릭 통합 모니터링 : Amazon Managed Prometheus & Grafana 기반 자동 구성합니다.
• 스택 전 영역 모니터링 : 학습 작업 → 컴퓨팅 → 네트워크 → GPU 하드웨어까지 사전 구성된 메트릭 제공합니다.
• 자동 확장 대응 : 클러스터 크기 증가 시 모니터링도 자동 확장합니다.
• 실시간 상태 확인 : 문제 원인을 빠르게 식별하여 다운타임 및 성능 저하 최소화합니다.
• 훈련 생산성 향상 : 분석 시간 단축으로 개발자·연구자 생산성 극대화합니다.

|
9. Post-Training
• 비즈니스 가치와 차별화는 모델 커스터마이징 단계에서 만들어집니다.
9-1. Supervised Fine-Tuning (SFT)
• 라벨이 있는 입력–출력 데이터를 사용하여 모델을 직접 학습시키는 방식입니다.
• 명확한 정답(ground truth)이 있을 때 효과적이며, 도메인 용어/문체를 학습시켜 전문 분야에 최적화 가능합니다.
[예시] 고객지원 Q&A, 요약(Summarization) 작업, 의료/법률/금융 등 전문 용어가 많은 도메인 적응

9-2. Reinforcement Learning 기반 Fine-Tuning (RL)
• 모델이 여러 답변을 생성하고, 그 결과에 대해 보상(Reward) 또는 패널티를 받아 더 나은 출력을 학습하는 방식입니다.
• 구성 요소
- Policy Model: 실제로 Fine-Tuning되는 모델(출력 생성)
- Reward Model 또는 Reward Function: 출력 품질을 평가하여 점수 부여
- Optimization Algorithm: Reward에 따라 모델 업데이트
- 복잡한 규칙이 많은 상황에서 좋은 성능을 보이며, 장문 추론이나 정책 준수에 매우 효과적
• 세부 유형
- RLHF (Reinforcement Learning from Human Feedback) : 인간이 라벨링한 선호 데이터로 보상 계산
- RLAIF (RL from AI Feedback) : AI가 Judge 역할을 하여 보상 계산하며, 대량의 평가가 필요할 때 인간 리소스 절감됩니다.
- RL from Verifiable Rewards : 정답을 프로그램적으로 검증 가능한 작업에서 사용하며 편향이 적고 확장성이 좋습니다. 예: 코드 실행 결과가 정확한지 자동 확인합니다.

9-3. Direct Preference Optimization(DPO)
• DPO는 RL과 유사하지만 완전한 RL은 아님. 보상 모델 또는 복잡한 RL 시스템 없이 선호 데이터만으로 모델을 최적화합니다.
• 학습 방식은 하나의 프롬프트에 2개의 답변을 보여주고 선호 신호를 학습하게 하여 어떤 응답이 더 바람직한지 모델이 이해하도록 합니다.
- 주관적 기준이 중요한 분야로 스타일, 톤 등 감성적 요소를 학습
- 챗봇의 말투/가치관/브랜드 특성을 반영하고 싶을 때 사용
- 장점은 구현이 쉬우며 비용이 적고 안정적인 학습이 가능

|
10. 커스터마이징 기법
10-1. 현실적인 문제
1) 복잡한 인프라 구성 부담
- SFT, RLHF, DPO 등 기법별로 필요한 구성요소가 모두 다릅니다.
- 데이터 수집·적재·전처리부터 파이프라인 구축까지 작업량이 큽니다.
2) 기법별 파이프라인 전부 따로 준비 필요
- 학습 방식이 다르다 보니 각기 다른 도구/환경 설정 필요합니다.
- 설정과 운영에 드는 시간과 리소스 증가됩니다.
3) 모델 평가 체계 구축 필요
- 성능 검증, 비교, 지속적인 품질 모니터링이 필수입니다.
- 테스트 데이터/지표 관리가 복잡해집니다.
4) 엔터프라이즈 수준의 거버넌스 요구
- 모델 접근 권한 관리합니다.
- 누가 어떤 데이터로 어떤 모델을 만들었는지 전 과정 추적(Lineage Tracking) 필요합니다.
- 내부 정책 및 컴플라이언스 준수 고려합니다.
5) 실제 비즈니스 가치보다 ‘배관 작업(Plumbing)’에 시간 소모
- 기술 자체보다 환경 셋업과 운영 문제 해결에 더 많은 자원이 들어갑니다.
- 정작 모델의 가치를 높이는 핵심 작업에 집중하기 어렵습니다.

10-2. SageMaker의 모델 커스터마이징 지원
1) 통합된 커스터마이징 플랫폼 제공
- 커스터마이징 전 과정을 하나의 환경에서 수행합니다.
- 복잡한 파이프라인 구축 없이 바로 활용 가능합니다.
2) 다양한 모델을 즉시 커스터마이징 가능
- Amazon Nova 시리즈
- GPT-OSS, Llama, Qwen, DeepSeek 등 다양한 공개 모델 지원합니다.
- 선택 폭이 넓어 목적에 맞는 모델 활용 용이합니다.
3) 모든 주요 미세조정 기법 지원
- Supervised Fine-Tuning(SFT)
- Reinforcement Learning(RL / RLHF / RLAIF 등)
- Direct Preference Optimization(DPO)
- 기법 간 전환도 쉬워 실험 효율 개선합니다.
4) 완전 관리형(fully managed) 환경 제공
- 인프라 설정/운영/스케일링을 AWS가 자동 처리합니다.
- 분산 학습 구성, 모니터링, 자원 최적화 등을 직접 신경 쓰지 않아도 됩니다.
- 엔지니어링 부담 감소 → 모델 품질 개선에 집중 가능합니다.

10-3. Serverless Training
• 문제 : 여전히 학습 인프라 구성, 운영 부담이 존재하며 플랫폼 관리에 시간을 낭비하고 모델 실험보다 인프라 세팅에 더 많은 리소스를 소모하는 비효율 발생 🡪 Serverless Training이 이를 해결합니다.
1) 완전 서버리스 학습 지원 : 컴퓨트 용량·클러스터 구성 고민 없이 즉시 훈련 가능
2) 간단한 실행 : 데이터 선택 + 모델 선택 → API/UI로 바로 학습 시작
3) 자동 자원 할당 및 스케일링 : 필요 시 자동 확장, 사용하지 않을 때 비용 절감
4) 인프라 관리 불필요 : 노드 관리, 장애 처리 등 모든 운영을 SageMaker가 담당
5) 모델 커스터마이징에만 집중 : 엔지니어링 부담 제거로 개발 생산성 향상

10-4. 모델 평가(Model Evaluation)
• 문제 : 파인튜닝 후 성능 향상의 확신이 어려우며 데이터에 따라 평가 방식이 다양. 그리고 기업 환경에서는 평가 결과의 신뢰성과 재현성이 필요한 현실 🡪 API 또는 UI 기반 완전 관리형 평가 기능 제공합니다.
• 평가 방식 지원
- 산업 표준 벤치마크(정량적 비교 가능)
- LLM-as-a-Judge: AI가 평가자 역할 수행 (품질, 스타일 등 주관적 기준 평가)
- Custom Metrics 정의: 도메인 특화 평가 가능
- 결과 비교를 통해 커스터마이징 효과 검증 가능
• 효과
- 파인튜닝 모델의 품질 개선 여부를 즉시 확인
- 평가 환경 구축 필요 없음 → 시간/비용 절감
- 객관적 + 주관적 품질 평가 모두 가능

10-5. Serverless Mlflow
• 문제 : 학습 중 loss, reward 등 지표 추적 필수지만 mlflow는 인프라 직접 설정, 서버 운영이 필요하며 팀별 관리가 복잡하고 비용이 부담합니다.
- SageMaker 내 완전 관리형 MLflow 서비스 제공
- 설정 없이 바로 실험 기록 가능
- UI/Studio 및 API 연동
- SageMaker Serverless Training과 자동 연계 -> 모든 학습 지표가 즉시 MLflow에 저장
• 효과
- 인프라 관리 부담 0
- 실험 메트릭 통합 관리 → 비교·추적·재현성 향상
- 개발자가 모델 개선에만 집중 가능

|
11. SageMaker에서 모델 커스터마이징을 사용하는 3가지 방식
11-1. Code-based Path (SDK 기반)
• ID 환경 제약 없이 사용 가능합니다. (JupyterLab / VS Code 내장 IDE 지원)
• 몇 줄의 코드로 빠르게 파인튜닝 시작합니다.
• 코드와 UI를 상호 전환하며 작업 가능합니다.
• 개발자 주도형 Workflow에 적합합니다.
11-2. UI 기반 Path (Point-and-Click Fine-Tuning)
• Studio UI에서 메뉴 선택만으로 파인튜닝 실행합니다.
• 주요 기능 흐름
1) 모델 선택 → “Customize with UI”
2) 학습 작업 이름 입력
3) 커스터마이징 기법 선택 (예: RLVR 활용 가능)
4) Reward Function 선택 또는 추가
5) 학습 데이터 선택
6) Serverless 학습 작업 실행
• 추가 지원 기능
- 학습 진행 모니터링
- 평가(Evaluation) 작업도 UI에서 수행
- Judge Model 선택 (LLM-as-a-Judge)
- 평가 지표 및 데이터셋 선택
- Serverless 평가 실행
• 완료 후:
- 지표/로그 확인
- 결과 다운로드 지원
- 원클릭 배포
- SageMaker Endpoint 또는 Bedrock으로 배포 가능
- Playground에서 모델 응답 테스트 가능
- Lineage 추적 : 어떤 데이터/설정/승인/평가가 사용되었는지 전체 변경 이력 확인
11-3. Agent-Guided Path
• 사용자 언어로 목적을 설명하면AI Agent가 커스터마이징 전체 과정을 설계 및 실행 지원합니다.
1) 사용 사례를 자연어로 입력하면, 질문을 통해 요구사항 명확화
2) Base Model 선택 안내
3) Use Case Specification 자동 생성 : 성공 기준(Success Tenets) 포함 → 이후 평가 기준으로 활용
4) 데이터 예시 자동 생성 → 사용자 검수 및 편집 가능
5) Data Generation Specification 생성
6) Synthetic Data 자동 생성 : 데이터 샘플 확인, (다양성, Responsible AI 등) 품질 지표 제공
7) Reward Function Template 자동 추천 및 생성(RLVR 예시)
8) 학습 작업 실행 및 모니터링
9) 평가 기준 검토 후 승인 시 자동 평가 실행
10) 평가 결과 비교(파인튜닝 모델 vs Base Model)
11) 클릭 한 번으로 SageMaker 또는 Bedrock에 배포
• 효과 : 데이터 생성 → 보상 모델 설계 → 학습 → 평가 → 배포 전체 자동화, ML 지식이 부족해도 대화만으로 모델 커스터마이징 가능합니다.

|
12. SageMaker AI 모델 개발의 3대 핵심 요소
1) Choice
- 다양한 기반 모델 선택 가능합니다.
- 미세조정(Finetuning) 방식 및 기술을 자유롭게 선택합니다.
- 사용자 인터페이스 선택 가능합니다. (SageMaker Studio UI, SDK, Agent 등)
- 개발자가 원하는 방식과 워크플로에 맞게 유연한 모델 개발이 가능합니다.
2) Efficiency (효율성 극대화)
- Serverless 경험을 기반으로 인프라 관리 부담 제거합니다.
- 모델 커스터마이징에 필요한 시간과 비용 크게 절감 : 기존 수개월 → 수일 수준으로 단축
- 빠른 실험·개발이 가능하여 비즈니스 가치 창출 속도 향상합니다.
3) Security & Governance (보안 및 거버넌스)
- 모델 변경 이력(Lineage) 추적 기능 제공합니다.
- IAM 기반 세밀한 접근 제어 지원합니다.
- VPC 내 안전한 실행 환경으로 보안 강화합니다.
- 모델 사용 주체/경로에 대한 투명한 가시성 확보합니다.
- 조직 차원의 안전한 AI 도입과 운영을 보장합니다.

|
13. Nova Forge
• Amazon은 기업이 보유한 고유한 지식과 데이터(조직 지식) 를 기반으로 맞춤형 AI 모델을 구축할 수 있도록 Nova Forge 프로그램을 제공합니다.
• 이를 통해 기반 모델(Foundation Model)의 일반 지식과 기업 고유 지식 간의 간극을 연결(Bridge the gap) 하여 기업만의 경쟁력 있는 AI 모델을 만들 수 있습니다.
13-1. 배경
• 기업은 고유한 지식과 데이터(IP) 를 보유하고 있습니다.
• 기존 Foundation Model은 일반적 지식 기반 → 기업 특화 능력 부족합니다.
• 기업 지식과 FM 지식 사이의 격차가 존재합니다.
13-2. 기존 기술의 한계
• RAG : 외부 지식 단순 참조하므로 모델 자체 능력 향상 없음, 컨텍스트 없으면 성능 저하합니다.
• LoRA 기반 파인튜닝 : 특정 영역만 부분 강화 → 확장 한계 가 있습니다.
• Open-weights 모델 확장 : 기존 기본 능력(예: 지시 따르기) 망각 위험합니다.
• 모델을 처음부터 자체 개발 : 비용, 시간, 인력 모두 막대 → 현실적 어려움이 있습니다.
13-3. Nova Forge의 핵심 가치
• 기업 데이터 기반으로 FM 자체를 확장합니다.
• 기본 역량 유지하면서 조직 특화 능력 부여합니다.
• 모델 품질 저하 없이 도메인 지식 강화합니다.
• 기존 방식 대비 효율적인 시간·비용 구조입니다.
13-4. SageMaker 기반 이유
• 초대규모 모델 학습을 위한 최적의 인프라입니다.
• 안정성, 거버넌스, 운영 기능까지 완비된 플랫폼입니다.
• Nova Forge는 SageMaker 위에서 제공 → 즉시 활용 가능합니다.
|
14. Amazon Nova 2
14-1. 모델 라인업
• 화요일 Matt Garman 발표, Nova 모델의 2세대(Second Generation) 공식 공개합니다.
• Nova 2 Lite : 공개/일반 사용 가능한 모델, Nova Forge 기반 커스터마이징에 즉시 활용 가능합니다.
• Nova 2 Pro, Nova 2 Omni : 현재 Early Access(사전 접근) 단계, 향후 더 고도화된 성능과 기능 제공 예정입니다.
14-2. 모델 성능 특징
• 타사 선도 모델과 동급 수준 성능입니다.
• 제3자 검증된 표준 벤치마크 테스트에서 검증 완료되었습니다.
• 경쟁 모델 대비 뒤처지지 않는 품질 확보합니다.
14-3. Nova Forge와의 시너지
• 처음부터 높은 모델 품질을 확보한 상태에서 기업 특화 모델 개발 가능합니다.

|
15. Nova Forge 설명
15-1. 모델 생성 (3단계)
• Pre-training : 기초 지식을 쌓는 단계
• Mid-training : 특정 분야 전문성을 주입하는 단계
• ost-training (SFT + RL) : 실제 환경에서 좋은 행동을 학습시키는 단계
15-2. SFT와 RL 차이
• SFT (지도학습 미세조정) : 정답 예시를 보여주고 따라하게 만드는 훈련합니다.
• RL (보상 기반 강화학습) : 정답 예시는 없고, 행동에 따라 보상/패널티를 줍니다.
15-3. Nova Forge가 주는 가치
• 모델 전 단계 체크포인트에 접근 가능 : 완전 기초부터 커스터마이징 가능합니다.
• 기업 고유 데이터 + AWS Nova 데이터를 섞어서 학습: 모델이 기본 지식 잃지 않게합니다.(=catastrophic forgetting 방지)
• RL을 고객 환경에서 직접 수행 가능 : 각 회사의 서비스 요구에 맞게 alignment 강화합니다.
• Push-button recipes로 훈련 파이프라인 자동화 : 개발 속도 빠르게합니다.
• Responsible AI toolkit 제공 : 안전성/정책 준수 보장합니다.
15-4. Data mixing technique 이 중요한 이유
• 데이터를 한쪽으로만 넣으면 기존 능력을 망각할 수 있습니다.(기초 언어 능력 저하)
• Nova Forge는 도메인 데이터 비중을 조절하며 섞는 기능 제공 : 필요한 분야만 더 강화, 나머지는 유지합니다.
15-5. Reddit 사례
• Nova Forge로 커뮤니티 콘텐츠 Moderation 모델 개발합니다.
• 기존 오픈소스 모델로는 정확도가 부족 → 도메인 특화 필요합니다.
• Nova Forge 덕분에 세계적인 모더레이션 모델을 직접 구축합니다.
15-5. Amazone Stores 활용 사례
• Amazon Stores 팀이 Nova Forge를 사용해 모델을 자신들의 쇼핑 도메인에 맞게 학습합니다.
• 도메인 특화 MMLU(쇼핑 분야 이해력) +9.8% 개선합니다.
• 일반 MMLU(공통 언어 능력) +2.7% 개선합니다.
→ 특정 도메인 성능을 올리면서도 기존 모델이 갖고 있던 기본 언어 능력을 잃지 않습니다.(무손실 개선)
• Nova Forge의 데이터 믹싱 기법이 Catastrophic Forgetting을 방지한다는 근거 사례입니다.

15-6. Reinforcement Learning 기능
• 기업이 직접 정의한 보상 함수(Reward Function)를 자신의 서비스/환경에서 그대로 적용 가능합니다.
• AWS에서 제공하는 API를 통해 실시간으로 RL 신호를 SageMaker로 전달 합니다.
• 모델이 실행되는 실제 애플리케이션 맥락에서 사용자 반응·품질 기준에 따라 즉시 모델 행동을 개선합니다.
• RL 적용 주기(학습 반영 빈도)를 자유롭게 조절 가능 : 원하는 만큼 반복적이고 빠른 모델 개선합니다.
• CoSign AI와의 협업 사례를 통해 요구사항 반영 : “데이터만 주는 것”이 아니라 실시간 양방향 학습 파이프 라인 구축합니다.
15-7. Nova Forge의 모델 구축 편의 기능
• Push-button Recipes 를 제공하여 가능한 한 쉽고 빠르게 시작할 수 있으며, 이후 필요에 맞게 유연하게 조정할 수 있습니다.
• CLI(왼쪽) 또는 **UI(오른쪽)**로 모든 작업을 수행할 수 있음. UI에서 시작 후 CLI로 이동하거나, CLI에서 시작 후 다시 UI로 이동하는 등 상호 전환이 가능합니다.
• Data Mixing UI : 도메인별로 데이터 비중을 세밀하게 조절 가능합니다.
15-8. SageMaker 기반 모니터링
• 학습 프로세스 모니터링 가능합니다.
• SageMaker 플랫폼에 의해 지원합니다.
• 학습 작업이 시작부터 끝까지 어떤 상태인지 전체 진행 상황 확인 가능합니다.
15-9. NovaForge로 빌드하는 모델의 소유권/보안 및 Nova 기반 코드
• NovaForge로 모델을 구축할 때 핵심은, Nova를 훈련시킨 동일한 코드 기반 위에서 모델을 만든다는 것입니다.
• 자체 데이터를 투입하면 그 도메인 지식이 Nova 기반 모델에 주입되며, 기업이 생성하는 각 모델을 우리는 “Novellas”라고 부릅니다.
• 만든 모델은 각자의 소유이며, Amazone은 해당 모델에 접근할 수 없으며, 데이터 또한 전적으로 보호됨
• ISV(솔루션 제공자) 경우 고객에게 이 모델을 제공하거나 고객이 추가 파인 튜닝하도록 허용하는 등
최대의 활용 자유도를 가질 수 있습니다.

15-10. RAI 설정(콘텐츠 모더레이션) 및 지원 서비스
• 콘텐츠 모더레이션 설정을 자유롭게 조정합니다.
• Reddit의 사례와 같이 모더레이션 모델을 직접 개발하는 경우 안전 제어를 꺼야 함 : 상황에 따라 켜고/끄고 강도 조절이 완전히 자유롭습니다.
• 모델 개발 전략에 대한 도움이 필요하다면 AWS Gen AI Innovation Center에서 전문가와 함께
당신의 비즈니스 DNA를 모델에 통합하는 작업도 지원합니다.

|
|
|