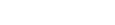|
|
안녕하세요, AI 서비스 & 솔루션 프로바이더 베스핀글로벌입니다.
AWS re:Invent 2025의 The future of Kubernetes on AWS을 확인해보시기 바랍니다.
|
☑️ Keynote
| 세션명 |
The future of Kubernetes on AWS |
| 세션코드 |
CNS205 |
| 발표일자 |
2025.12.05 |
| 강연자 |
Miki Stefaniak, Eswar Bala, Niall Mullen |
| 키워드 |
1. 컨트롤 플레인 혁신
2. 프로비저닝된 컨트롤 플레인
3. ECR 기능 강화
4. 운영 및 관측성 개선
5. EKS 기능 확장 (Platform) |
| 핵심 내용 |
EKS는 컨트롤 플레인 아키텍처를 AWS 저널 기반으로 재설계해 최대 10만 노드까지 확장 가능한 울트라 클러스터를 제공하며 예측 가능한 성능을 위한 프로비저닝 모드도 지원합니다. 또한 ECR 아카이빙·서명 기능과 향상된 네트워크 관측성 등 운영 편의성이 강화되었습니다. 더불어 GitOps와 AWS 리소스까지 아우르는 EKS Capabilities로 플랫폼 구축과 운영 복잡성을 크게 줄였습니다.
|
|
1. Kubernetes의 현황과 EKS 역할

- Kubernetes의 보편화: 2024년 CNCF 설문조사에 따르면, 80%의 엔터프라이즈가 프로덕션 환경에서 Kubernetes를 사용하고 있으며, 이는 2023년의 66%에서 증가한 수치입니다.
- Kubernetes의 인기 요인: Kubernetes가 대중화된 가장 큰 이유는 단순성(Simplicity)으로 분석됩니다.
- Kubernetes는 SRE들이 수년간 만들어온 Bash 스크립트, 런북, 쿡북 등을 선언적이고(declarative) 조정 가능한(reconciling) API로 묶어놓은 단순한 관리 방식입니다.
- 그 외 주요 요인으로는 일관성(Consistency)과 확장성(Extensibility)이 꼽힙니다.
- 일관성: AWS, 온프레미스, 다른 클라우드, 엣지 등 어디서든 실행 가능합니다.
- 확장성: CRD 모델을 통해 컨테이너 오케스트레이션을 넘어 비즈니스 운영 전반에 사용될 수 있습니다.
- EKS의 발전: 2017년 re:Invent에서 EKS 프리뷰가 발표된 이후 8년이 경과했습니다.
- 초기에는 관리형 Kubernetes 컨트롤 플레인 제공에 집중했습니다.
- 이후 Kubernetes 생태계의 새로운 표준이 된 오픈소스 프로젝트를 지원하고, 컨트롤 플레인을 넘어 애드온(add-ons), 데이터 플레인으로 확장했습니다.
- 최근에는 EKS Capabilities를 발표하여 클러스터 외부의 복잡한 플랫폼 구축 관리까지 지원합니다.
2. EKS의 기본 구성 요소 및 최근 개선 사항
2-1. EKS의 기본 레이어 및 개발자 경험
-
EKS의 목표: 고객의 목표는 인프라 운영이 아닌 비즈니스 가치 전달이며, EKS 팀의 목표는 프로덕션 준비가 된 Kubernetes 환경 구축에 필요한 기본 구성 요소를 제공하는 것입니다.
-
인프라 레이어: 컴퓨팅, 네트워킹, 스토리지는 변하지 않으며, AWS는 이를 Kubernetes 네이티브 방식으로 제공하는 데 중점을 둡니다.
-
컨트롤 플레인: Kubernetes 운영에서 가장 어려운 부분이며, 현재 AWS에서 Kubernetes를 운영하는 거의 모든 고객(넷플릭스 포함)이 EKS를 사용합니다.
-
관리 도구 및 보안: 거버넌스, 규정 준수, 보안이 다음 레이어이며, EKS 팀은 이 영역에서도 지원을 확대하고 있습니다.
-
개발자 친숙도 변화: 최근 데이터에 따르면 개발자의 Kubernetes 친숙도가 감소하는 추세입니다.
이는 Kubernetes의 인기가 떨어진 것이 아니라, Kubernetes가 Linux처럼 스택의 한 계층이 되어 개발자가 배포(Deployments), 작업(Jobs), ML 워크플로우 등 익숙한 도구를 사용할 때 Kubernetes를 의식하지 않게 되었음을 의미합니다.
-
컨테이너 레지스트리 (ECR): ECR은 하루에 20억 건 이상의 이미지 풀을 처리하며 AWS 컨테이너 세계의 숨은 영웅으로 간주됩니다.
2-2. ECR의 2025년 주요 개선 사항

- 향상된 스캐닝 (Enhanced Scanning): Inspector와의 통합을 통해 이미지에 대한 고급 스캐닝을 제공합니다.
- 취약 이미지 실시간 인벤토리: 스캔 후 취약한 이미지가 현재 실행 중인 클러스터(수십, 수백, 수천 개)에서 어디에 있는지 쉽게 확인할 수 있는 기능을 몇 달 전에 출시했습니다.
- 인증된 풀스루 캐시 (Authenticated Pull-Through Cache): ECR에서 Docker Hub나 ECR Public 같은 업스트림 레지스트리에서 이미지를 가져올 수 있으며, 이제 ECR 간 풀스루 캐시 기능이 추가되어 리전 및 계정 간에도 캐시가 가능합니다.
- 2025년 주요 론치:
- 태그 불변성 (Tag Immutability): 보안 및 규정 준수 목적으로 특정 이미지(예: latest 태그)는 변경할 수 없도록 설정할 수 있는 유연성을 제공합니다.
- re:Invent 신규 론치:
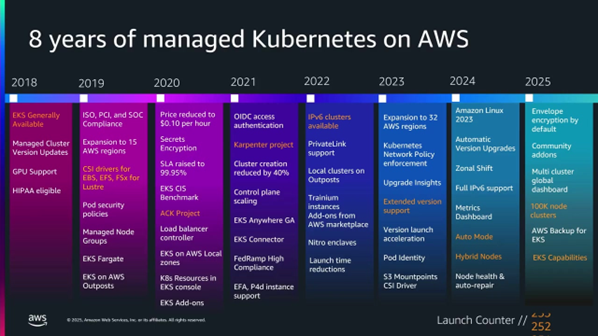
- 보관 (Archival): 규정 준수를 위해 이미지를 보관해야 하지만 주 레지스트리에서 사용할 필요가 없는 경우, 이미지 마지막 풀 시점을 기준으로 별도의 저렴한 스토리지 클래스로 아카이브할 수 있습니다. 필요 시 다시 복원 가능합니다.
- 관리형 이미지 서명 (Managed Image Signing): 별도의 인프라 운영 없이 완전히 자동화된 관리형 서명을 제공하며, AWS Signer 및 CloudTrail과 통합됩니다.
3. EKS 클러스터 관리 및 업그레이드 혁신
3-1. Kubernetes 버전 지원 및 클러스터 가시성 강화
-
EKS의 원칙: EKS는 항상 바닐라 업스트림 Kubernetes를 실행하며, 컨포먼스(Conformance)를 매우 중요하게 여깁니다.
-
업그레이드 관리: Kubernetes 업그레이드는 피할 수 없는 부분으로 인식하고 있으며, 이에 대한 고통을 인지하고 있습니다.
-
클러스터 인사이트 (Cluster Insights): EKS가 클러스터를 스캔하여 다음 버전으로 업그레이드할 때 영향을 줄 수 있는 요소(예: 사용 중단된 API, 너무 오래된 버전 사용)를 찾아 인사이트를 제공합니다.
-
사용자는 이제 인사이트를 온디맨드로 새로 고칠 수 있어 수정 후 결과를 즉시 확인할 수 있습니다.
-
Kubernetes 버전 지원 가속화: 지난 2년간 EKS에서 새로운 버전이 출시될 때마다 45일 이내에 지원을 완료했으며, 앞으로도 이 45일 창을 유지할 것을 보장합니다.
-
EKS 글로벌 대시보드 (EKS Global Dashboard): 고객 피드백을 반영하여 수십 개의 계정, 수십 개의 리전에 걸쳐 있는 클러스터의 위치를 파악하기 어렵다는 문제를 해결하기 위해 출시되었습니다.
-
특징: 진정한 글로벌, 교차 계정, 교차 리전 대시보드를 제공하여 중앙 집중식 인벤토리를 제공합니다.
-
목적: 주로 경영진 수준의 대시보드로, 월요일 아침에 클러스터 버전을 확인하고 업그레이드가 필요한 대상을 파악하는 워크플로우에 적합합니다.
3-2. 관찰 가능성(Observability) 및 네트워킹 개선
4. 문제 해결 및 비용 관리 혁신
4-1. EKS MCP 서버 및 CloudWatch Container Insights
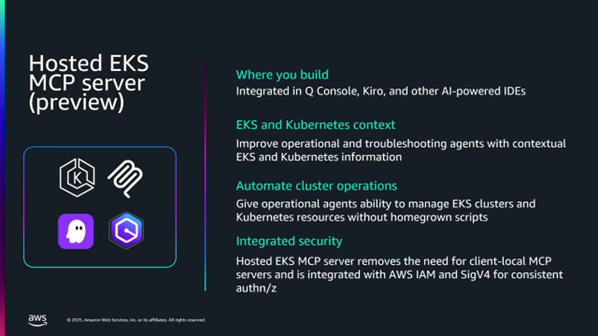
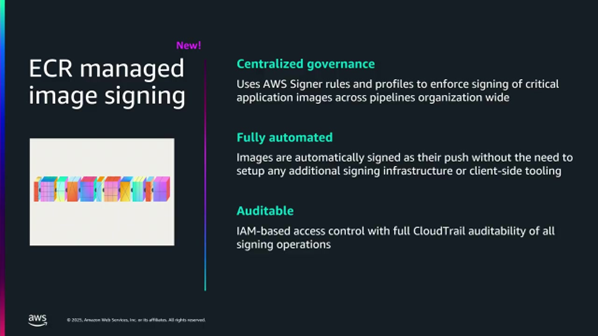
- 호스팅된 EKS MCP 서버: 초기에는 사용자가 직접 관리해야 사용하지 않겠다는 피드백이 많아, 지난주에 호스팅 버전을 공개 프리뷰로 출시했습니다.
- 활용: 문제 해결(Troubleshooting) 및 시작(Getting Started)에 중점을 둡니다.
- 내부 지식 활용: 7년간 축적된 Kubernetes 실패 사례에 대한 런북이 MCP 서버에 내장되어 있어, 사용자가 지원팀이 참고하는 지식을 직접 조회할 수 있습니다.
- Q 통합: EKS 콘솔에서 문제가 발생했을 때 Q를 클릭하면, 백그라운드에서 MCP 서버와 자동으로 통합되어 실패 원인을 더 깊이 있게 파악할 수 있습니다.
- CloudWatch Container Insights: EKS의 네이티브 관찰 가능성 도구로, 가장 쉬운 버튼(Easy Button) 역할을 합니다.
- 최근 EBS 메트릭, 상세 GPU 메트릭, 애플리케이션 신호 지원 등이 추가되었습니다.
- 장점: 어떤 메트릭을 스크랩하고 어떤 알람을 설정할지 고민하지 않고, Kubernetes 모니터링 스택의 의견 기반(opinionated) 버전을 제공합니다.
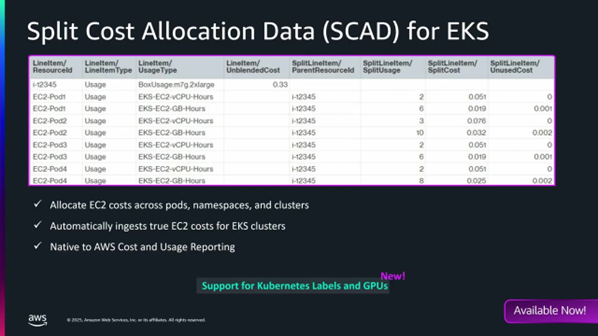
- 비용 가시성: Kubernetes의 효율성(하나의 인스턴스에 여러 애플리케이션 실행)은 비용 가시성을 저해합니다.
- 해결책: KubeCost(오픈소스) 파트너십 또는 완전 관리형 버전을 통해 비용 할당을 관리할 수 있습니다.
- 최근 업데이트: 작년에 발표된 기능에 대한 주요 요청 사항이었던 Kubernetes 레이블 지원 및 GPU 지원이 몇 주 전에 EKS에 지원되었습니다.

4-2. 보안 및 플랫폼 관리 기능 강화
- 교차 계정 파드 ID (Cross-account Pod Identity): 작년에 출시된 파드 ID 기능을 확장하여, 실제 프로덕션 워크로드에서 흔히 사용되는 다중 계정 환경을 지원합니다.
- 세션 토큰 지원: 단일 정책을 사용하여 네임스페이스 접두사와 동일한 S3 버킷만 읽을 수 있도록 하는 등 세분화된 권한 설정이 가능해졌습니다.
- 클러스터 삭제 보호 (Cluster Deletion Protection): 인프라 코드 도구 버그 등으로 인한 원치 않는 클러스터 삭제 위험을 줄이기 위해 다른 서비스와 유사한 클러스터 삭제 보호 기능을 추가했습니다.
- EKS 애드온 (EKS Add-ons): AWS가 더 많은 무거운 짐을 지는 테마에 따라 확장되고 있습니다.
- 커뮤니티 애드온: Metric Server, External DNS와 같이 흔히 사용되는 애드온이 이제 커뮤니티 애드온으로 제공됩니다.
- EKS용 AWS 백업 지원: 상태 저장(Stateful) 워크로드의 백업 및 규정 준수 보고를 쉽게 하기 위해 출시되었습니다.
- 특징: ECS용 AWS 백업 지원이 큐브콘에서 출시되었으며, 에이전트리스, 완전 관리형이며, 교차 계정/교차 리전을 지원합니다.
- 복원: 특정 네임스페이스만 복원하거나 기존/새 클러스터로 복원할 수 있는 유연한 접근 방식을 제공합니다.
- EBS 통합: EBS 팀과의 긴밀한 협력을 통해, EBS의 새로운 기능(향상된 데이터 보호, 빠른 초기화, 볼륨 복제 등)이 출시되는 당일 EBS CSI 드라이버를 통해 EKS에서 바로 사용 가능하도록 보장합니다.
5. 하이브리드 및 데이터 플레인 혁신
5-1. EKS의 배포 범위 및 데이터 플레인 관리

- EKS의 배포 범위: EKS는 모든 리전, 모든 가용 영역에 존재하며, 클라우드뿐만 아니라 온프레미스에서도 실행됩니다.
- 하이브리드 노드 (Hybrid Nodes): 작년에 출시된 이 기능은 온프레미스 인프라 지원을 위한 새로운 접근 방식입니다.
- 특징: 컨트롤 플레인은 클라우드에 두고 워커 노드를 온프레미스에 두는 방식이며, 클라우드 연결만 있으면 됩니다.
- EKS Anywhere와의 비교: EKS Anywhere는 완전히 온프레미스/에어 갭 방식인 반면, 하이브리드 노드는 연결성이 있을 때 더 쉬운 접근 방식입니다.
- 올해 기능: Bottlerocket 지원, Cilium 지원 확대, 온프레미스 네트워킹 설정에 대한 인사이트 제공 등이 있습니다.
- Auto Mode (완전 관리형 데이터 플레인): 작년 re:Invent에서 출시된 완전 관리형 데이터 플레인이며, 가장 Kubernetes 네이티브적이고 컨포먼트한 방식이라고 평가됩니다.
- 작동 방식: EC2와 협력하여, Auto Mode 이전에는 사용자가 EC2 인스턴스와 모든 컨트롤러를 실행했지만, Auto Mode에서는 EBS 드라이버, Carpenter, 로드 밸런서 컨트롤러와 같은 컨트롤러 실행 책임을 AWS가 가져갑니다.
- EC2 관리형 인스턴스: EC2 인스턴스는 계정 내에서 실행되지만 AWS가 관리합니다.
- 반복 개선: 올해 정적 용량, 고급 네트워킹 옵션(파드를 별도 서브넷에 실행), 리전 확장, 더 빠른 이미지 풀 등이 추가되었습니다.
5.2. EKS Capabilities: 클러스터 외부 관리 확장
- EKS Capabilities 소개: EKS 출시 이후 7년 만에 가장 큰 업데이트로, 클러스터가 프로덕션 준비가 되어도 애플리케이션 배포 및 외부 AWS 서비스 연결(S3 버킷, Elastic 등)을 위해 플랫폼 구축이 필요하다는 점을 해결합니다.
- 플랫폼 관리 확장: Kubernetes 주변의 플랫폼 구축에 필요한 무거운 짐을 관리하는 방향으로 확장합니다.
- 배포 관리 (Deployments): Argo CD의 관리형 버전을 제공합니다.
- 철학: 대다수 고객이 사용하는 기존 커뮤니티 표준이 있으면 이를 관리형으로 제공하는 것이 Capabilities의 접근 방식입니다.
- AWS 통합: GitOps의 고충인 Secrets 관리를 위해 Secrets Manager와 네이티브 통합을 추가했으며, CodeCommit과의 통합도 제공합니다.
- 네트워크 동기화 관리: 자체 관리 시 불가능했던 네트워크 동기화 트래픽을 백그라운드에서 관리하여 교차 계정/교차 리전에서도 네트워크 연결 걱정 없이 작동하게 합니다.
- ACK 및 Crow 관리: 두 오픈소스 프로젝트에 대한 관리형 Capabilities를 출시했습니다.
- ACK (AWS Controllers for Kubernetes): Kubernetes 네이티브 방식으로 AWS 리소스를 관리하는 방법입니다.
- Crow: AWS 리소스에 대한 추상화를 구축하고 이를 API로 게시하는 방법입니다.
- 개발자 경험 개선: 개발자가 S3 버킷을 위해 팀에 티켓을 여는 대신, Kubernetes 애플리케이션과 인프라를 Kubernetes 네이티브 방식으로 정의할 수 있게 됩니다.
- 플랫폼 관리 비교: EKS만 사용하는 자체 관리 플랫폼과 Capabilities 및 Auto Mode를 결합했을 때, AWS가 더 많은 부분을 관리해주는 것을 보여줍니다.
6. 넷플릭스의 EKS 대규모 마이그레이션 사례(Neil Mullen)
6-1. 넷플릭스의 컴퓨팅 규모와 특이성

- 넷플릭스 컴퓨팅 배경: 3억 명의 고객을 위한 웹사이트 운영, 대규모 개인화, 매주 수천 시간 분량의 8K 비디오 촬영 및 인코딩(백 카탈로그 포함), 광고 및 게임 사업 등으로 인해 컴퓨팅 수요가 매우 높습니다.
- 특징: 넷플릭스의 지출 중 컴퓨팅 기반 비율은 다른 대규모 고객보다 50%에서 100% 더 높습니다.
- 기존 컴퓨팅 환경: 15년 전 클라우드로 전환했으며, 컴퓨팅의 다수는 여전히 성숙한 EC2 워크플로우에서 Java 및 Node 서비스를 직접 실행합니다.
- Titus 플랫폼: 서비스 수 기준으로 대다수의 컴퓨팅은 8년 전 자체 개발한 Titus 플랫폼에서 실행됩니다.
- Titus는 대규모 멀티테넌트 컨테이너 플랫폼(Container as a Service)이며, 약 5년 전 내부적으로 Mesos에서 Kubernetes로 전환되었습니다.
- 넷플릭스 환경의 특이성:
- 지역 가용성 모델: 4개의 핵심 스트리밍 리전을 운영하며, 문제가 발생하면 약 5분 만에 전체 리전을 전환합니다.
- 일일 트로프(Trough): 일일 사이클에서 피크 대비 트로프가 최대 45%까지 발생하며, 이는 하루 중 수십만 개의 CPU가 유휴 상태임을 의미합니다. 넷플릭스는 이 유휴 시간을 활용하기 위해 예약 인스턴스(RI)를 97% 활용합니다.
- 규모 계획: 계획 시 고려하는 것은 일반적인 상태 유지 시작 속도나 리전 대피 속도가 아니라, 1억 명의 사람들이 동시에 시청하는 상황에 대비해야 합니다.
- EKS 채택 이유: 넷플릭스는 자체적으로 모든 것을 구축해왔으나, "필요할 때만 구축한다"는 엔지니어링 원칙에 따라, 이제는 AWS가 제공할 수 있는 부분(규모 관련 미분화된 작업)을 오프로드하여 규모를 남의 문제로 만들고자 EKS를 채택했습니다.
6.2. EKS 마이그레이션 과정 및 결과
- 마이그레이션 통합 작업: 약 9개월 동안 EKS 팀과 협력하여 EKS의 규모를 필요한 수준으로 맞추고 통합 작업을 수행했습니다.
- 주요 통합 사항: 자체 아이덴티티 모델을 IAM과 통합하고, Kubernetes 로그가 CloudWatch로 들어가도록 통합했습니다.
- 마이그레이션 실행: 전체 플릿(Fleet)을 단일 분기(Quarter) 내에 마이그레이션하기로 결정하고, 목표보다 11일 초과하여 모든 컨테이너를 새로운 EKS 컨트롤 플레인에서 실행하도록 전환했습니다.
- 발견된 한계: 3월 당시 EKS는 단일 클러스터 내 120,000개 파드를 선호하지 않는다는 것을 발견했습니다. (현재 초거대 규모 발표를 통해 개선되었을 것으로 기대하고 테스트 예정입니다.)
- 성공적인 경험: 마이그레이션 경험이 매우 순조로웠기 때문에, 파드를 어느 클러스터에 배치할지 결정하는 페더레이션 레이어까지 EKS로 전환하는 일정을 앞당겼습니다.
- 향후 계획:
- Titus 데이터 플레인: 현재 가상 Kubelet과 6만 줄의 커스텀 코드로 이루어진 Titus 데이터 플레인을 스톡 Kubelet으로 전환하는 작업을 연말까지 완료할 예정이며, 이는 향후 EKS 데이터 플레인 마이그레이션의 문을 열어줄 것입니다.
- EKS Hybrid Nodes 및 Auto Mode: 엣지 사용 사례 및 OS 관리를 없애기 위해 검토 중입니다.
- 2026년 목표: 얇은 컨테이너 사용 사례를 실험하고, 데이터 플레인을 EKS로 마이그레이션하는 스토리를 공유하는 것입니다.
7. EKS의 미래 로드맵 및 비전
7-1. 고객의 요구사항과 EKS의 가속화 전략
-
고객의 공통된 요구: 많은 고객들이 Kubernetes를 표준으로 사용하고 툴링을 활용하고 싶어 하지만, 클러스터, 업그레이드 등 어려운 부분은 생각하고 싶지 않다는 공통된 요구사항을 가지고 있습니다.
-
기술 비전문 기업 지원: 헬스케어, 게임, 제약 등 순수 기술 기업이 아닌 곳들은 대규모 오픈소스 프로젝트를 직접 운영하고 관리할 시간과 전문성이 부족합니다.
-
EKS의 역할: 오픈 표준을 활용하고 AWS와 결합하여 고객의 가치 실현 시간(Time to Value)을 가속화하는 것이 EKS의 역할입니다.
-
워크로드 다양성: AI/ML, 스트리밍, 인코딩, 게임, 웹 애플리케이션, 데이터 처리 등 모든 유형의 워크로드가 EKS에서 실행되고 있습니다.
-
향후 목표: AI/ML 외에도 상태 저장 워크로드(Spark, Flink)의 업그레이드를 더 쉽게 만드는 것에 집중할 것입니다.
7-2. EKS 발전 단계 및 향후 3년 우선순위
- EKS 발전 단계:
- 초기 (2018년): 가장 어려운 부분인 관리형 컨트롤 플레인 (etcd, 스케일링, 패치)에서 시작했습니다.
- 확장: 하이브리드(AWS 외부 컴퓨팅 관리) 및 플랫폼 구성 요소 관리로 확장했습니다.
- 현재 (올해): EKS Capabilities를 통해 클러스터 외부에 있는 구성 요소의 무거운 짐을 계속 가져가고 있습니다.
- 궁극적인 비전: 클러스터 생성조차 필요 없이 애플리케이션 매니페스트만 제공하면 EKS가 모든 무거운 짐을 지고 Kubernetes를 제공하는 세상입니다.
- 향후 3년 우선순위:
- 모든 규모에서의 중요 워크로드 패턴: 오늘 논의된 모든 워크로드 패턴과 계속 커지는 규모 요구사항을 지원하며, 단일 클러스터의 최대 규모를 넘어서면 여러 클러스터에 걸친 워크로드 실행을 쉽게 만드는 데 집중합니다.
- AWS 통합: 다른 AWS 팀과 협력하여 Kubernetes 네이티브 고객을 위해 올바른 통합을 구축하는 것이 Mike와 Ishwar의 주요 업무입니다.
- 워크로드 위치 충족: EKS Anywhere(자체 운영)부터 EKS DRO(클라우드 내)까지, 워크로드가 있는 곳에서 만날 수 있도록 Outpost의 새로운 서버 유형 지원 등 관리를 개선할 것입니다.
- 플랫폼 구축 단순화: 관리형 Capabilities를 지속적으로 출시하여, EKS 운영을 위해 거대한 플랫폼 팀이 필요 없도록 만들 것입니다.
- 혁신 가속화: 커뮤니티 및 오픈소스 프로젝트에서 기존 표준이 있으면 이를 가져와 실행하는 철학을 유지합니다 (예: 관리형 Argo).
- 예외: Cluster Autoscaler 대신 Karpenter를 구축한 것처럼, 기존 표준보다 더 나은 것을 만들 수 있다고 판단되면 새로운 프로젝트를 구축할 것입니다.
|
| |
| |
|
|