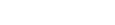|
|
안녕하세요, AI 서비스 & 솔루션 프로바이더 베스핀글로벌입니다.
AWS re:Invent 2025의 [Observability & Security unite: Unify your data in Amazon CloudWatch]을 확인해보시기 바랍니다.
|
☑️ Keynote
| 세션명 |
Observability & Security unite: Unify your data in Amazon CloudWatch |
| 세션코드 |
COP361 |
| 발표일자 |
2025.12.04 |
| 강연자 |
Nikhil Kapoor, Avinav Jami, Chandra |
| 키워드 |
Security, Observability, Audit & Compliance, Log data, Data fragmentation, Plumbing, CloudWatch Logs, CloudTrail, VPC Flow Logs, 3rd-party, Unified log storem, Collect, Curate, Storage, Analytics, Pipelines, OCSF / OELm, Grok Processor, Cross-account, Cross-region, S3 Tables, Facets, SIEM, Distributed centralization / Centralize and distribute |
| 핵심 내용 및 요약 |
ㆍ조직 내 로그·데이터 파편화 문제
ㆍ문제의 근본 원인: 공통 로그 소스가 각자 다른 스토어로 복제
ㆍCloudWatch를 “통합 로그 스토어”로 쓰게 하는 전략
ㆍ큐레이션 기능 강화 (Pipelines)
ㆍ중앙 저장소 & Cross-account / Cross-region 중앙화
ㆍAnalytics & Insights – Facets, S3 Tables
ㆍS&P Global 사례: 복잡한 파이프라인 → CloudWatch 중심 아키텍처로 단순화
ㆍ권장 아키텍처 패턴과 실무 팁 |
|
Observability & Security unite: Unify your data in Amazon CloudWatch
조직 내 로그 분산 문제를 해결하기 위한 CloudWatch 중심의 통합 로그 아키텍처 전략에 대해 소개합니다.
|

1. 조직 내 로그·데이터 파편화 문제
1-1. 팀·도구·데이터 사일로
- 보안팀(Security), 관측/운영팀(Observability), 감사/컴플라이언스(Audit) 팀이 따로 존재합니다.
- 각 팀은 목적에 맞는 전문 도구를 사용합니다.
- 보안팀: 전용 시큐리티 분석 도구, SIEM
- 관측팀: APM, Metrics/Traces/Logs 도구 여러 개
- 감사팀: 별도의 저장소/분석 시스템
- 이 자체는 나쁜 것이 아니지만, 실제 사고·장애가 발생하면 문제가 드러납니다.
- 보안팀은 방화벽 로그에서 많은 Deny를 보며 공격으로 인지합니다.
- 애플리케이션 팀은 트래픽 스파이크만 보고 “고객이 늘었나?” 하고 스케일아웃을 고민합니다.
- 서로 다른 도구·로그만 보면서 문제를 엇갈리게 이해 → 빠른 공통 인사이트 부재를 확인합니다.
1-2. 근본 원인: 로그 소스는 같은데, 저장소·파이프라인이 분리
- 실제로 쓰는 로그 소스는 거의 동일합니다.
- AWS 서비스 로그, CloudTrail, 애플리케이션 로그, CrowdStrike/Okta 같은 SaaS 로그 등
- 그러나 각 팀/툴로 보내기 위해 동일 로그를 여러 번 복제·전송해야 합니다.
- CloudWatch → Kinesis → S3 → SIEM, 또는 S3에서 또 다른 SIEM, Data Lake로 복제 등
- 이러다 보면 “거미줄 같은 로그 ETL 파이프라인” 이 생기고, 파이프라인 장애, 재처리(backfill), 버전 관리, 포맷 변경 시 영향 범위가 폭발적으로 커지며, 신규 계정/리전/워크로드 온보딩 때마다 같은 복잡성을 반복합니다.

1-3. CloudWatch를 통합 로그 스토어로: Collect → Curate → Store → Analyze
- AWS 서비스로 로그 수집을 확대합니다.
- 이미 65+ 서비스에서 CloudWatch로 바로 로그 수집 가능
- 여기에 30개 추가 서비스(예: NLB, CloudFront, Bedrock 에이전트 로그 등)를 지원
- 3rd-party 로그 수집 : Managed Connector 방식으로 CrowdStrike, Okta 등 10개 파트너 로그를 “코드 없이” CloudWatch로 수집합니다. (향후 계속 파트너 확대 예정)
- 조직 단위(Org-level)로 활성화합니다.
- CloudTrail, VPC, NLB 등 주요 로그를 AWS Organizations 레벨에서 켜기/끄기 지원
- 멀티 계정 환경에서 일일이 계정별 세팅을 하지 않아도 되고, 보안·컴플라이언스 요구 사항을 중앙에서 강제할 수 있음
1-4. Curate – 큐레이션(변환·정규화)
- OCSF & OEL 용 Out-of-the-box Transformer : 보안·옵저버빌리티 표준 스키마에 맞춰 로그 필드를 정규화합니다.
- Pipelines + Grok Processor : Pipelines 기능을 통해 로그를 흐르게 하면서, 필드 추가/삭제/변환, 문자열 파싱/정규표현식 파서(Grok) 적용, 태그·컨텍스트 필드 추가합니다. (예: 앱 이름, 환경, 팀명 등)
- source / type 정보 자동/수동 태깅 : CloudWatch가 알고 있는 “데이터 소스/종류” 메타데이터를 로그에 집어넣고, Custom 로그에도 태그를 추가해 “어떤 서비스/애플리케이션의 어떤 타입 로그인지”를 쉽게 필터링 가능, 즉, 리소스명·로그 그룹명 수준을 넘어서 “업무 서비스 단위” 로 분석할 수 있게 만듭니다.

1-5. Store – 저장 & 중앙화
- 유연한 보존 정책·버전 관리가 가능합니다.
- CloudWatch 중앙화 기능으로 어떤 데이터는 보안·감사 목적 때문에 수년간 보존해야 하고, 어떤 데이터는 운영상 며칠~몇 주면 충분합니다.
- Cross-account / Cross-region 중앙화합니다.
- 여러 계정·리전의 로그를 규칙 기반으로 단일 계정의 중앙 스토어로 집계
- 중앙 스토어에 들어갈 때 추가 변환/필터링을 적용해 “보안 버전” 로그를 만들 수 있음
- 멀티리전의 경우 활성-활성(Active-Active) 백업 아키텍처도 가능

1-6. Analyze – Analytics & Insights
- S3 Tables 통합합니다. (Apache Iceberg)
- CloudWatch에 저장된 로그를 Iceberg 테이블로 노출
- Athena, Redshift, EMR 등 AWS 분석 서비스나 Iceberg 호환 써드파티 도구에서 바로 쿼리 가능
- CloudWatch 쪽에서는 추가 PUT/복제/스토리지 비용 없이 관리
- Facets – 차세대 인덱싱을 경험합니다.
- 로그 인사이트 페이지에서 쿼리를 작성하기 전에 필드별 값 분포(예: status, errorType, serviceName) 를 GUI로 확인
- Facet 값 클릭만으로 필터링/드릴다운 → “어디서부터 파야 하지?” 하는 초기 탐색이 매우 쉬워짐
- 복잡한 쿼리 단계로 들어갈 때는 Query Gen 같은 기능을 함께 사용

2. S&P Global 사례: 대규모 멀티계정 로그 아키텍처 개선
2-1. 회사 및 환경 소개
- 1800년대부터 이어진 금융 데이터·벤치마크 제공 업체로 S&P 500 지수로 유명해졌습니다.
- 전 세계 50개 오피스, 10개 데이터센터를 보유하고 있습니다.(주로 네트워크·연결용)
- 멀티리전·다수의 AWS 계정, 수많은 VPC와 리소스 → 로그 데이터 볼륨이 엄청 큽니다.

2-2. 이해관계자 요구사항
- Raw Logs – 중앙 로그 아카이브 계정 : 법무·컴플라이언스: 원본(raw) 로그를 변경 없이, 불변(immutable) 상태로 보존해야 합니다.
- Curated Logs – 보안 전용 계정(Security tooling account) : 클라우드 보안팀: 위협 탐지·정책 위반 모니터링에 최적화된 정제된 보안 로그가 필요합니다.
- Local Access – 각 비즈니스 유닛 계정 : 애플리케이션/비즈니스 팀: 로컬 계정에서 바로 로그 검색·트러블슈팅 가능해야 합니다.
- Security Operations 팀 : Threat Intelligence, Incident Response용으로 특화된 뷰 필요
- Log querying – 모두의 공통 요구 : 손쉽게 쿼리하고 필요한 로그를 빨리 찾을 수 있어야 합니다.
- SIEM 비용 최적화 : 외부 상용 SIEM 사용 중 → 모든 로그를 다 집어넣으면 비용 폭발, 반드시 필요한 이벤트만 선택적으로 SIEM에 인제스트해야 합니다.

2-3. 기존 아키텍처: 복잡한 CloudWatch Subscriptions + 다수의 S3 버킷
- CloudWatch 중앙화 기능을 쓰기 전에는 각 계정(VPC/서비스) 로그 그룹 → 여러 CloudWatch Subscription 으로 중앙 계정 S3 버킷, Security 계정 S3 버킷, SIEM용 S3/Firehose 등으로 복제해야 했습니다.
- 각 목적지마다 별도 S3 버킷을 관리해야 하고, 파이프라인마다 에러·재처리·권한 설정·버전 관리를 직접 해야 했습니다.
2-4. 새로운 아키텍처: CloudWatch-native 중앙화로 단순화
- AWS 팀과 협업해 아키텍처를 재설계: CloudWatch 로그 중앙화 기능을 활용해 소스 계정에서 CloudWatch Logs에 들어온 로그를 중앙 계정, 보안 계정 등으로 자동 복제합니다.
- 수동으로 짰던 Subscription·Lambda·Firehose 파이프라인 상당수를 제거합니다.
- S3 버킷 수와 중간 컴포넌트 수가 크게 감소하였습니다.
- “Plumbing이 CloudWatch native로 바뀌었고, 게다가 그 부분은 무료다” 라고 언급하였습니다.
- 효과
- 아키텍처 단순화
- 운영 비용 및 복잡성 감소
- S&P 측 추산으로 20–25% 비용 절감 기대
- Raw Archive 계정(Immutable), Security Tooling 계정, 로컬 계정 접근 모두 구현 성공 → 이해관계자 요구사항을 충족하면서도 단일 아키텍처로 통합합니다.

2-5. 실무 체크포인트
- Aggregate with a plan : “그냥 로그를 다 모으기”가 아니라 어떤 목적(보안, 운영, 컴플라이언스)으로 어디에, 얼마나 오랫동안, 어떤 형태로 저장·집계할지 명확한 전략을 세우고 수집해야 합니다.
- Meet your teams where they are
- 각 팀은 이미 익숙한 도구·워크플로우가 있음
- “이제부터 이 도구만 써라” 식의 One-size-fits-all 강요는 실패
- 대신, 공통 로그 스토어를 만들어 데이터를 공유하되, 팀은 자신의 도구에서 그 데이터를 활용할 수 있게 하는 방향
- Iterative approach
- 한 번에 모든 계정·리전을 갈아엎기보다 작은 범위에서 시작
- 경험을 쌓으면서 점진적으로 확장 이 방식이 위험을 줄이고, 조직 내 도입·적응도를 높임
3. 배포 모델 & 데모 요약
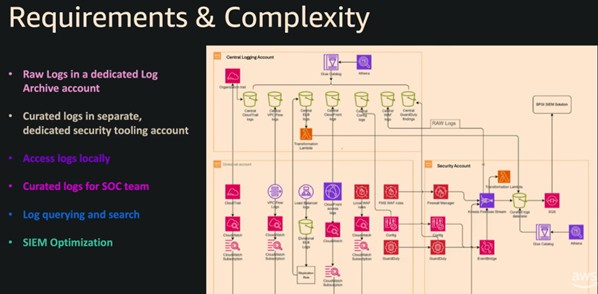
3-1. 비용 모델 설명
- 기존 CloudWatch Logs의 세 가지 축은 그대로입니다.
- Ingestion(수집 데이터 양), Storage(저장 용량), Query(스캔 데이터량)
- Facets, S3 Tables, Pipelines, Org-level enablement 등은 → 추가 기능 비용 없이 포함됩니다.(기본 요금 안에 들어감)
- Ingestion 클래스: Standard Class: 인덱스·알람·실시간 분석 등에 최적화되어 있습니다.
- Infrequent Access Class: 장기 보존·컴플라이언스용입니다.(비용 1/2 수준, 일부 기능 제한
- 중앙화(Centralization) 비용
- 첫 번째 집계본(aggregated copy): 중앙 계정으로 복제 시 추가 ingestion 비용 없음
- 두 번째 카피부터: ingestion 비용 없이 전송 비용 0.05$ 정도만 각 계정의 Storage/Retention은 독립적으로 과금
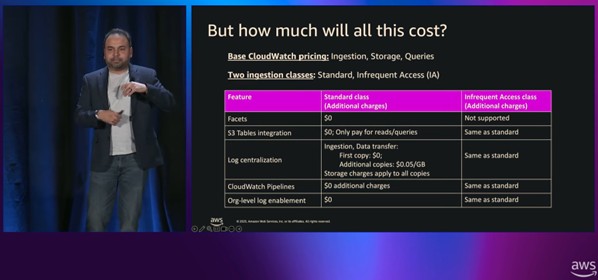
3-2. 배포 모델 1 – Distributed Centralization
- 각 계정에 필요한 로그는 그대로 수집(로컬 팀이 활용) 동시에 중앙 Observability 계정과 Security 계정으로 필요한 로그만 CloudWatch가 Managed 방식으로 복제됩니다.
- 로컬 계정: Dev/SRE가 실시간 트러블슈팅에 사용
- Observability 계정: 전체 서비스 상태를 가로지르는 관측 뷰
- Security 계정: 보안·위협 탐지에 최적화
- 모두 동일 원본 로그를 공유하지만, 각 환경에서 독립적으로 변환·보존 정책·도구를 사용할 수 있습니다.

3-3. 배포 모델 2 – Centralize and Distribute
- S&P Global이 사용한 모델에 가깝습니다.
- 전체 로그를 우선 중앙 계정으로 모은 뒤: 그곳을 “단일 진실 원본(single source of truth)” + 컴플라이언스 아카이브로 사용, 필요한 데이터만 선별·필터링해서 보안 계정, SIEM, 기타 도구로 배포(distribute)합니다.
- 멀티 리전일 경우, 중앙화 과정에서 DR(재해복구)용 활성-활성 구성도 가능합니다.
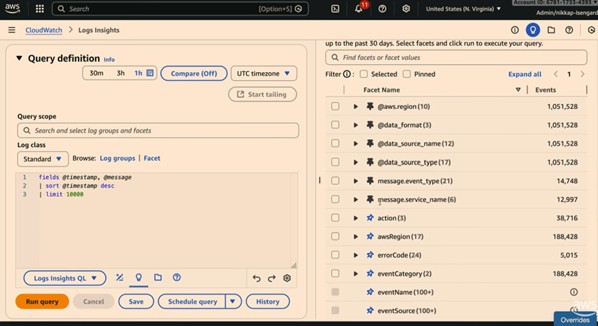
3-4. 데모 – Facets + CloudTrail 연계 분석
- 상황: 결제 시스템(PayStream)에서 결제 실패가 발생합니다.
- CloudWatch Logs Insights 페이지에서: Facets를 통해 에러 유형, 서비스 이름, 계정/리전을 쿼리 없이 즉시 확인, payment-processor 서비스와 특정 에러 타입에 문제가 집중되어 있음을 발견합니다.
- 이후 쿼리를 실행해 어떤 계정/리전에서 결제 실패가 많이 발생하는지 집계, CloudTrail 데이터 소스를 선택해 해당 Lambda 함수 설정이 누군가에 의해 잘못 변경된 것을 찾음, 변경한 사용자 이름이 “Colprit”로 의도적으로 재미있게 설정되어 있습니다.
- facets로 “어디서 문제를 파기 시작할지” 를 빠르게 좁힌 뒤, CloudTrail처럼 다른 데이터 소스와 연결해 원인 이벤트(설정 변경)를 추적 가능합니다.
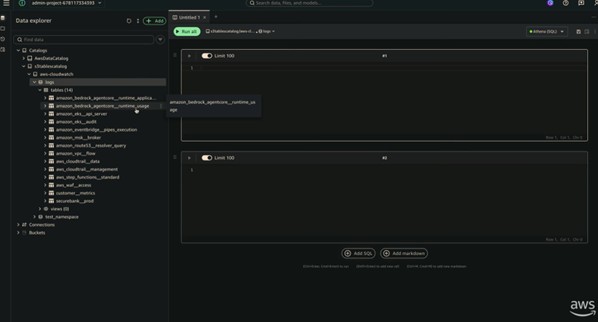
3-5. 데모 – S3 Tables + SageMaker Studio 통합
- CloudWatch 로그가 S3 Tables(Iceberg)로 노출되면, SageMaker Unified Studio나 Athena, Redshift 등에서 별도의 복제 작업 없이 같은 데이터를 바로 분석 가능합니다.
- SRE/개발자는 CloudWatch에서 문제를 해결합니다.
- 동시에 Product Manager 등 비기술 팀은 SageMaker Studio에서 같은 로그 데이터를 다른 데이터셋(고객·매출 데이터 등)과 조인해서 “어떤 고객이 영향을 받았는지”, “영향 범위가 어떻게 되는지”를 스스로 분석할 수 있습니다.
- 서로 다른 페르소나가 같은 원본 데이터를 다른 도구에서 공유하는 구조입니다.
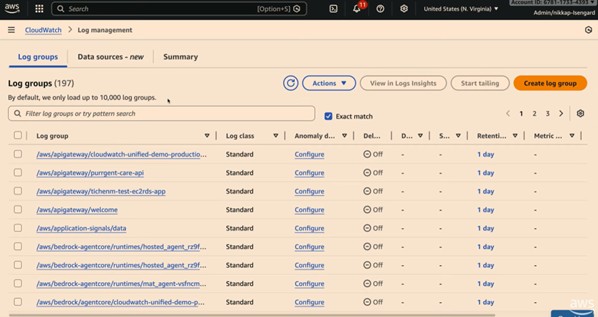
3-6. 데모 – 새 로그 관리(Log management) & 데이터 소스 UI
-
새로운 CloudWatch Logs 관리 페이지: 계정 전체 로그 인제스트량, 저장량, 최근 쿼리, 데이터 보호 정책 등 한눈에 파악, “어디에서 스파이크가 났는지”, “어떤 데이터 소스가 가장 큰 비중인지” 등을 상단 요약에서 확인 가능 합니다.
-
Data source 기반 경험: VPC Flow Logs / CloudTrail / Bedrock runtime 등, CloudWatch가 자동으로 매핑한 “데이터 소스별”로 로그를 볼 수 있음, 각 데이터 소스마다 기본 스키마(필드 목록)을 보여주고, 여기서 바로 S3 Tables 연동을 켤 수 있습니다.
-
S3 Tables 연동: 특정 데이터 소스만 선택하여 S3 Tables에 노출하거나, 여러 소스를 한 번에 선택해 통합 테이블로 노출 가능, 한 번 설정하면 이후 들어오는 로그는 자동으로 Iceberg 테이블에 반영합니다.
4. 마무리
4-1. 데이터 파편화는 기술 문제가 아니라 “조직+아키텍처 문제“
- 팀/도구/스토어가 분리되면서 같은 로그 데이터가 여러 번 복제되고, ETL 파이프라인이 복잡해지며, 인사이트 속도가 느려집니다.
4-2. CloudWatch를 보안+관측 통합 로그 스토어로 사용하는 방향
- 수집(Collect) → 큐레이션(Curate) → 저장(Store) → 분석(Analyze)
- 각 단계에 맞춰 CloudWatch 기능(Managed Connectors, Pipelines, 중앙화, S3 Tables, Facets 등)을 조합합니다.
4-3. 팀별 도구·워크플로우는 유지하되, 데이터만 한 곳으로 모으는 전략
- S&P Global처럼 이해관계자(법무·보안·비즈니스·SecOps·SIEM) 요구를 모두 만족시키면서 아키텍처를 단순화하고 비용까지 줄이는 것이 가능합니다.
4-4. 배포 모델은 한 번에 “통합 스토어 완성”이 아니라, 빌딩 블록에서 출발합니다.
|
| |
|
|